溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
計算機及操作系統原理:
OS
32bit , 64bit , 2^32=4G 2^64幾乎無窮大
CPU線路復用
PAE:Physical Address Extension 物理地址擴展
32bit,+4bit = 64G
程序具有局部性, 置換策略
空間局部性,時間局部性
CPU具有多級緩存 多級緩存靜態RAM
N路關聯
緩存縮影
路數越多命中幾率越大
逐級置換
CPU只跟一級緩存打交道
Write through 通寫
Write Back 回寫 數據在丟失的時候寫入主存
顯卡 Video Card 需要與CPU直接交互
PCI-E SSD M2
IO Port 一片連續端口 總線復用
poll機制 通知機制
中斷控制器 Interrupt Controller
臨界區 有可能產生競爭的地方
DMA:直接內存訪問
OS:VM
CPU:
時間,切片
緩存,緩存當前程序數據
進程切換:保存現場、恢復現場
內存分隔
4K,page , page frame(頁框)
指令,數據,堆,棧
進程描述結構
線性地址 虛擬地址 頁目錄
物理地址
目錄是一種映射關系
內存,將物理地址轉換成線性地址 可以實現內存保護 空間映射
I/O操作 中斷
內核 --> 進程
CPU有兩種模式 :用戶模式,內核模式
CPU 4層環模式
模擬 仿真
進程狀態:
Ready
Sleeping
可打斷
不可打斷
進程與操作系統之間關系: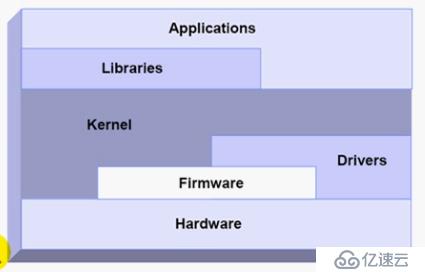
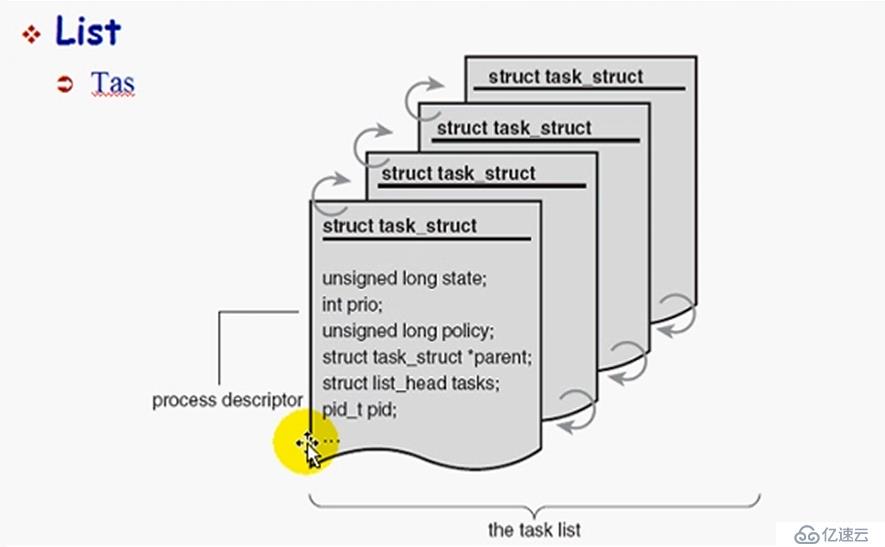
進程描述符
進程元數據
雙向鏈表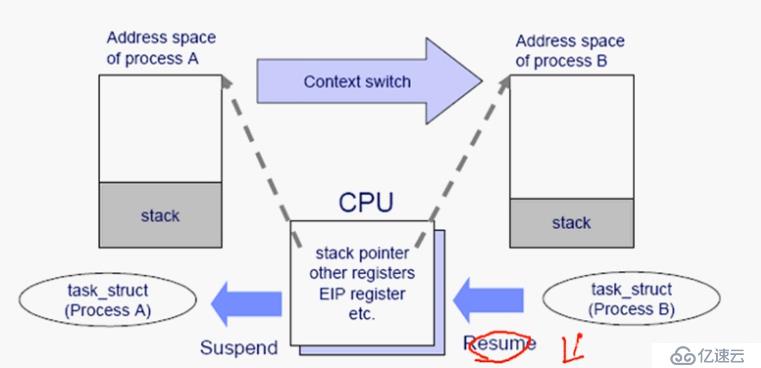
linux支持進程搶占
系統時鐘,內部時鐘頻率 tick 時鐘中斷
進程類型:
交互式進程(I/O)
批處理進程(CPU密集型)
實時進程(Real-time)
CPU:時間片長,優先級低
IO :時間片短,優先級高
Linux優先級:priority
實時優先級:1-99,數字越小,優先級越低
靜態優先級:100-139,數字越小,優先級越高
-20 0 19 100 ,139 nice為0 對應靜態優先級 100
實時優先級比靜態優先級高
ps -e -o class,rtprio,pri,nice,cmd
nice值:調整靜態優先級
有中括號表示內核線程
調度類別:
實時進程:
SCHED_FIFO First In First out
SCHED_RR Round Robin
SCHED_Other:用來調度100-139之間的進程
動態優先級:
dynamic priority = max(100,min (static priority -bonus +5,139) )
手動調整優先級:
100-139 nice
nice N COMMAND
renice -n # PID
chrt -p [prio] PID
1-99
chrt -f -p [prio] PID
chrt -r -p [prio] PID
Linux系統139個隊列
掃描隊列 99-1,100-139 活動隊列和過期隊列 兩者對換
linux2.6以后 CPQ:Complete Fair Scheduler SCHED_Other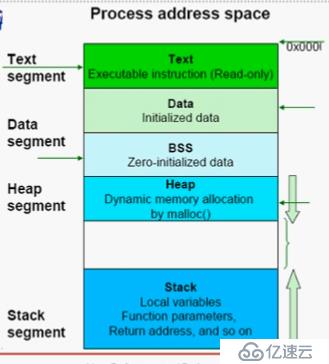
Kernel --> init
init fork():系統調用
task_struct
Memory -->Parent
COW :Copy On Write
RHEL6.4
tick less 無時鐘中斷
interrupt-driven
硬中斷
軟中斷
深度睡眠
一級緩存 I1 指令1,D1 Data1
SMP 對稱多處理器 一個CPU插槽叫一個socket
NUMA 非統一內存訪問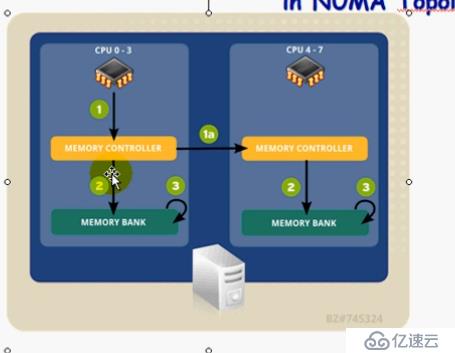
numastat 命令
numactl命令
numad命令
CPU affinity:CPU姻親關系
taskset:綁定進程至某CPU上
for example :
taskset -p mask pid
taskset -p -c 0-2,7 101 將101進程綁定在cpu0,1,2,7上
應該將中斷綁定至那些非隔離的CPU上,從而避免那些隔離的CPU處理中斷程序;
echo CPU_MASK > /proc/<irp number>/smp_affinity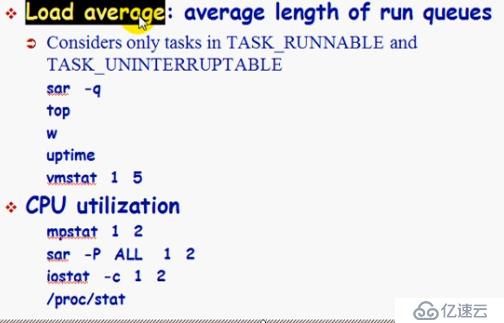
rpm -qf sysstat
mpstat
vmstat
sar -w 上下文切換的次數
taskset -p -c 0 16380
虛擬化環境:
PA —>HA —>MA
虛擬機轉換:PA—>HA
GuestOS, OS
Shadow PT
Memory:
TLB:提升性能
Hugetable page
hugetlbfs 文件系統
cat /proc/meminfo | grep Hugepages
sysctl -w vm.nr_hugepages=10 啟用大頁面

strace :
strace COMMAND :查看命令的syscall
strace -p PID :查看已經啟動進程的syscall
-c :中輸出其概括信息;
-o FILE :將追蹤結果保存至文件中,以供后續分析使用;
slab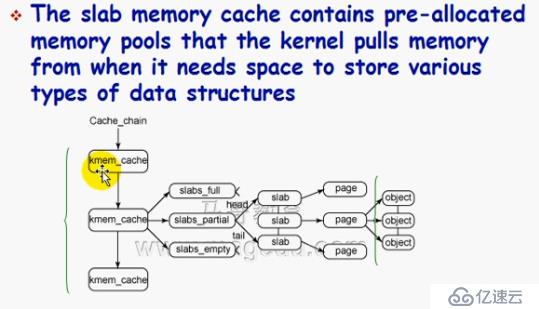
Strategies for using memory
1、降低微型內存對象的系統開銷
slab
2、縮減慢速子系統的服務時間
使用buffer cache 緩存文件元數據
使用page cache緩存DISK IO;
使用shm完成進程間通信;
使用buffer cache ,arp cache 和connetion tracking提升網絡IO性能
內存耗盡,系統崩潰
Tuning page allocation
物理內存的過量使用是以swap為前提的:
超過物理內存一部分
Swap
Tuning overcommit
ls /proc/1 oom_score
slabtop命令
slab cache
ARP cache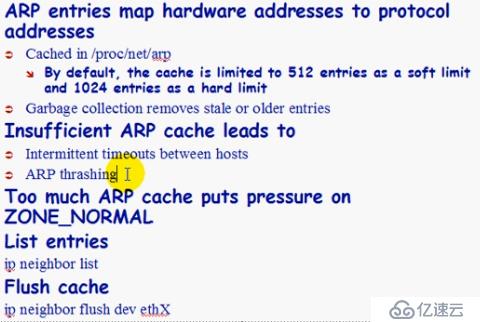
Tuning ARP cache
Page cache

vfs_cache_pressure
0:不回收dentries和inodes;
1-99 :傾向于不回收;
100:傾向性與page cache 和 swap cache相同;
100+:傾向于回收;
使用swap時會使用到page-cluster 虛擬化環境會使用到 
Anonymous pages
進程間通信使用匿名頁
/proc , /sys
CPU使用,內存使用
性能指標,關閉不必要進程
性能調優:
進程管理,CPU
內存調優
I/O
文件系統
網絡子系統
調優思路:
性能指標,定位瓶頸
綜合調優
系統級別調優工具:
SystemTap
Oprofile
Valgrind
Perf
進程間通信管理類命令
ipcs -l
ipcrm
sharememory
shmmni:系統級別,所允許使用的共享內存段上限;
shmall :系統級別,能夠為共享內存分配使用的最大頁面數;
shmmax:單個共享內存段的上限;
Message
msgmnb:單個消息隊列的上限,單位為字節;
msgmni:系統級別,消息隊列個數上限;
msgmax:單個消息大小的上限,單位為字節;
按需調整,一般情況都是調大
Tuning pdflush
1、周期性,2、觀察式 3、臟頁占有率
手動清寫臟緩存和緩存
內存耗盡時
Out-of-memory killer

oom-adj
-17:disables the oom_killer for that process
-16-15 :協助計算oom-score
oom-adj超高,oom-score分數越大,被殺死幾率越大
內存泄露查看方法:
valgrind --tool=memcheck cat /proc/$$/maps
內存子系統需要調節的幾大類
HugePage :TLB
IPC
pdflush
slab
swap
oom
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





