溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹如何利用C#實現最基本的小說爬蟲,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
前言
作為一個新手,最近在學習C#,自己折騰弄了個簡單的小說爬蟲,實現了把小說內容爬下來寫入txt,還只能爬指定網站。
爬的目標:http://www.166xs.com/xiaoshuo/83/83557/
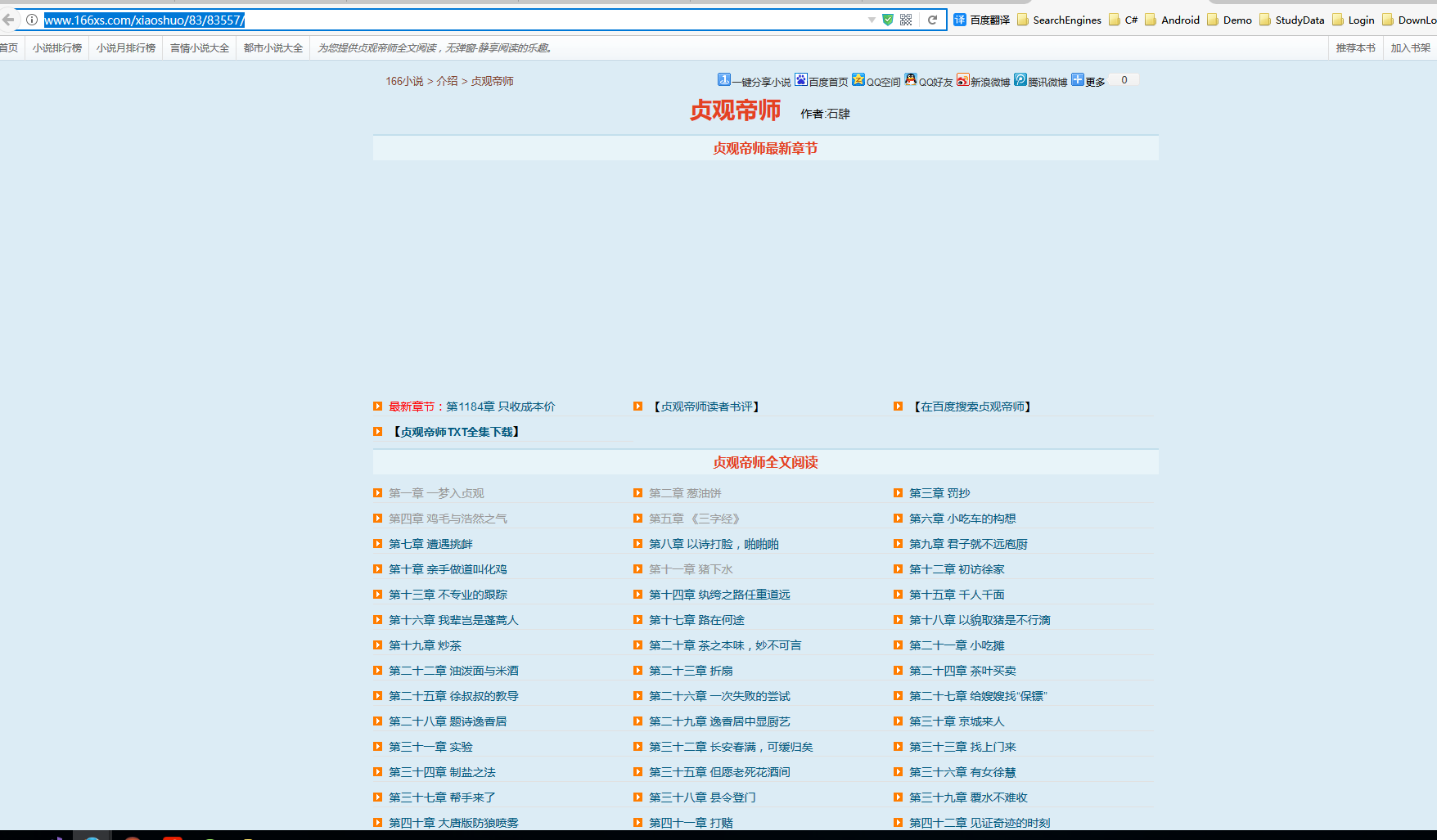
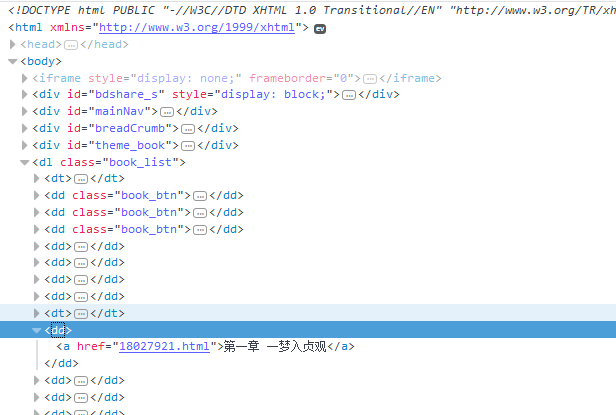
一、先寫HttpWebRequest把網站扒下來
這里有幾個坑,大概說下:
第一個就是記得弄個代理IP爬網站,第一次忘了弄代理然后ip就被封了。。。。。
第二個就是要判斷網頁是否壓縮,第一次沒弄結果各種轉碼gbk utf都是亂碼。后面解壓就好了。
/// <summary>
/// 抓取網頁并轉碼
/// </summary>
/// <param name="url"></param>
/// <param name="post_parament"></param>
/// <returns></returns>
public string HttpGet(string url, string post_parament)
{
string html;
HttpWebRequest Web_Request = (HttpWebRequest)WebRequest.Create(url);
Web_Request.Timeout = 30000;
Web_Request.Method = "GET";
Web_Request.UserAgent = "Mozilla/4.0";
Web_Request.Headers.Add("Accept-Encoding", "gzip, deflate");
//Web_Request.Credentials = CredentialCache.DefaultCredentials;
//設置代理屬性WebProxy-------------------------------------------------
WebProxy proxy = new WebProxy("111.13.7.120", 80);
//在發起HTTP請求前將proxy賦值給HttpWebRequest的Proxy屬性
Web_Request.Proxy = proxy;
HttpWebResponse Web_Response = (HttpWebResponse)Web_Request.GetResponse();
if (Web_Response.ContentEncoding.ToLower() == "gzip") // 如果使用了GZip則先解壓
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (var Zip_Stream = new GZipStream(Stream_Receive, CompressionMode.Decompress))
{
using (StreamReader Stream_Reader = new StreamReader(Zip_Stream, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
}
else
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (StreamReader Stream_Reader = new StreamReader(Stream_Receive, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
return html;
}二、下面就是用正則處理內容了,由于正則表達式不熟悉所以重復動作太多。
1.先獲取網頁內容
IWebHttpRepository webHttpRepository = new WebHttpRepository(); string html = webHttpRepository.HttpGet(Url_Txt.Text, "");
2.獲取書名和文章列表
書名

文章列表
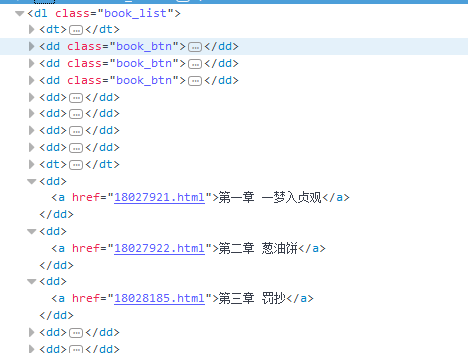
string Novel_Name = Regex.Match(html, @"(?<=<h2>)([\S\s]*?)(?=</h2>)").Value; //獲取書名 Regex Regex_Menu = new Regex(@"(?is)(?<=<dl class=""book_list"">).+?(?=</dl>)"); string Result_Menu = Regex_Menu.Match(html).Value; //獲取列表內容 Regex Regex_List = new Regex(@"(?is)(?<=<dd>).+?(?=</dd>)"); var Result_List = Regex_List.Matches(Result_Menu); //獲取列表集合
3.因為章節列表前面有多余的<dd>,所以要剔除
int i = 0; //計數
string Menu_Content = ""; //所有章節
foreach (var x in Result_List)
{
if (i < 4)
{
//前面五個都不是章節列表,所以剔除
}
else
{
Menu_Content += x.ToString();
}
i++;
}4.然后獲取<a>的href和innerHTML,然后遍歷訪問獲得內容和章節名稱并處理,然后寫入txt
Regex Regex_Href = new Regex(@"(?is)<a[^>]*?href=(['""]?)(?<url>[^'""\s>]+)\1[^>]*>(?<text>(?:(?!</?a\b).)*)</a>");
MatchCollection Result_Match_List = Regex_Href.Matches(Menu_Content); //獲取href鏈接和a標簽 innerHTML
string Novel_Path = Directory.GetCurrentDirectory() + "\\Novel\\" + Novel_Name + ".txt"; //小說地址
File.Create(Novel_Path).Close();
StreamWriter Write_Content = new StreamWriter(Novel_Path);
foreach (Match Result_Single in Result_Match_List)
{
string Url_Text = Result_Single.Groups["url"].Value;
string Content_Text = Result_Single.Groups["text"].Value;
string Content_Html = webHttpRepository.HttpGet(Url_Txt.Text + Url_Text, "");//獲取內容頁
Regex Rege_Content = new Regex(@"(?is)(?<=<p class=""Book_Text"">).+?(?=</p>)");
string Result_Content = Rege_Content.Match(Content_Html).Value; //獲取文章內容
Regex Regex_Main = new Regex(@"( )(.*)");
string Rsult_Main = Regex_Main.Match(Result_Content).Value; //正文
string Screen_Content = Rsult_Main.Replace(" ", "").Replace("<br />", "\r\n");
Write_Content.WriteLine(Content_Text + "\r\n");//寫入標題
Write_Content.WriteLine(Screen_Content);//寫入內容
}
Write_Content.Dispose();
Write_Content.Close();
MessageBox.Show(Novel_Name+".txt 創建成功!");
System.Diagnostics.Process.Start(Directory.GetCurrentDirectory() + \\Novel\\);三、小說寫入成功

C#是一個簡單、通用、面向對象的編程語言,它由微軟Microsoft開發,繼承了C和C++強大功能,并且去掉了一些它們的復雜特性,C#綜合了VB簡單的可視化操作和C++的高運行效率,以其強大的操作能力、優雅的語法風格、創新的語言特性和便捷的面向組件編程從而成為.NET開發的首選語言,但它不適用于編寫時間急迫或性能非常高的代碼,因為C#缺乏性能極高的應用程序所需要的關鍵功能。
以上是“如何利用C#實現最基本的小說爬蟲”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





