溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python中pandas庫的基本操作方法”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python中pandas庫的基本操作方法”吧!
pandas是什么?

是它嗎?
。。。。很顯然pandas沒有這個家伙那么可愛。。。。
我們來看看pandas的官網是怎么來定義自己的:
pandas is an open source, easy-to-use data structures and data analysis tools for the Python programming language.
很顯然,pandas是python的一個非常強大的數據分析庫!
讓我們來學習一下它吧!
1.pandas序列
import numpy as np import pandas as pd s_data = pd.Series([1,3,5,7,np.NaN,9,11])#pandas中生產序列的函數,類似于我們平時說的數組 print s_data
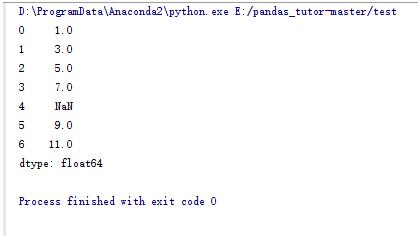
2.pandas數據結構DataFrame
import numpy as np
import pandas as pd
#以20170220為基點向后生產時間點
dates = pd.date_range('20170220',periods=6)
#DataFrame生成函數,行索引為時間點,列索引為ABCD
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
print data.shape
print
print data.values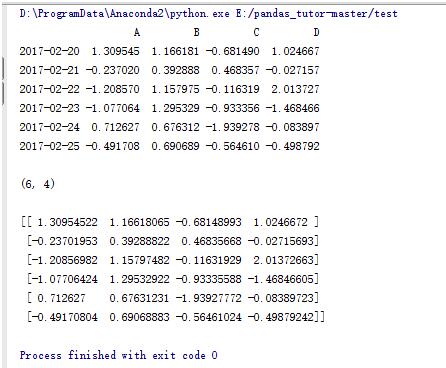
3.DataFrame的一些操作(1)
import numpy as np
import pandas as pd
#設計一個字典
d_data = {'A':1,'B':pd.Timestamp('20170220'),'C':range(4),'D':np.arange(4)}
print d_data
#使用字典生成一個DataFrame
df_data = pd.DataFrame(d_data)
print df_data
#DataFrame中每一列的類型
print df_data.dtypes
#打印A列
print df_data.A
#打印B列
print df_data.B
#B列的類型
print type(df_data.B)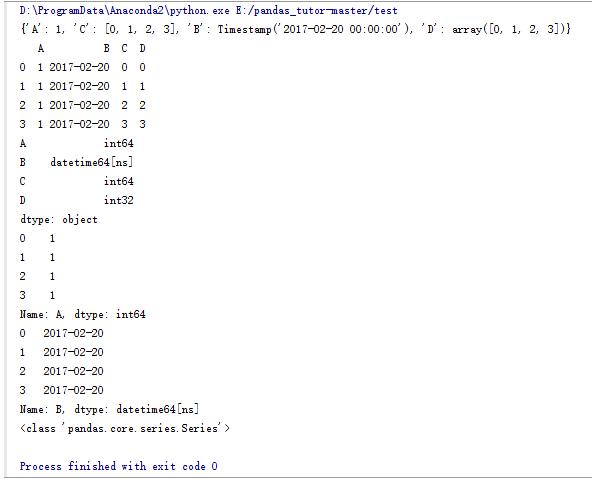
4.DataFrame的一些操作(2)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
#輸出DataFrame頭部數據,默認為前5行
print data.head()
#輸出輸出DataFrame第一行數據
print data.head(1)
#輸出DataFrame尾部數據,默認為后5行
print data.tail()
#輸出輸出DataFrame最后一行數據
print data.tail(1)
#輸出行索引
print data.index
#輸出列索引
print data.columns
#輸出DataFrame數據值
print data.values
#輸出DataFrame詳細信息
print data.describe()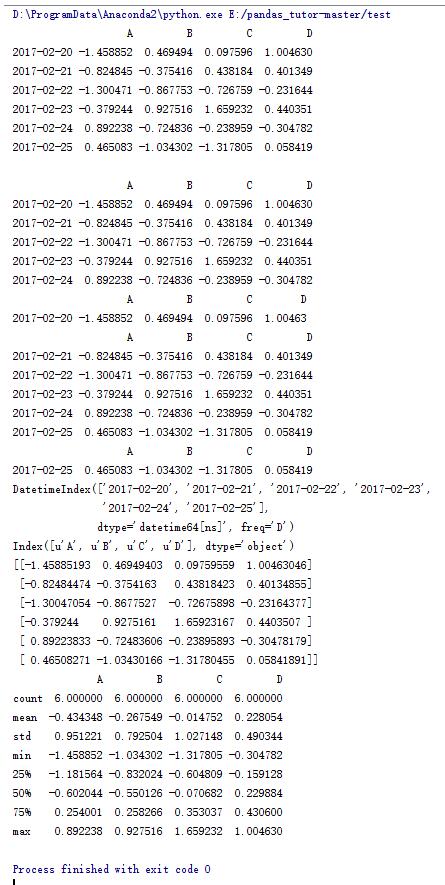
5.DataFrame的一些操作(3)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
print
#轉置
print data.T
#輸出維度信息
print data.shape
#轉置后的維度信息
print data.T.shape
#將列索引排序
print data.sort_index(axis = 1)
#將列索引排序,降序排列
print data.sort_index(axis = 1,ascending=False)
#將行索引排序,降序排列
print data.sort_index(axis = 0,ascending=False)
#按照A列的值進行升序排列
print data.sort_values(by='A')
6.DataFrame的一些操作(4)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#輸出A列
print data.A
#輸出A列
print data['A']
#輸出3,4行
print data[2:4]
#輸出3,4行
print data['20170222':'20170223']
#輸出3,4行
print data.loc['20170222':'20170223']
#輸出3,4行
print data.iloc[2:4]
輸出B,C兩列
print data.loc[:,['B','C']]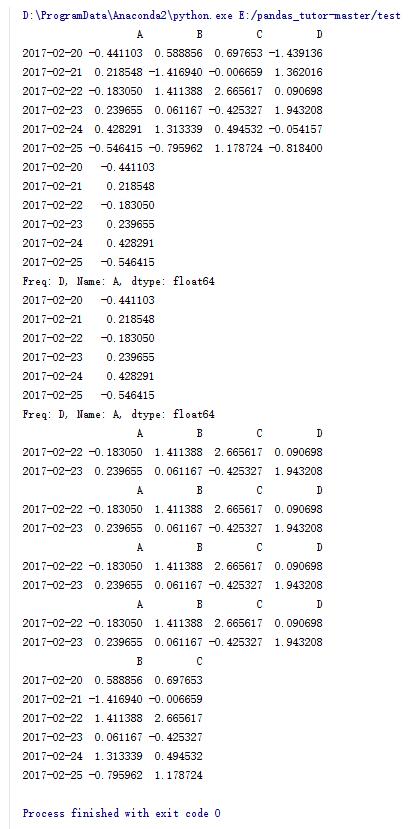
7.DataFrame的一些操作(5)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#輸出A列中大于0的行
print data[data.A > 0]
#輸出大于0的數據,小于等于0的用NaN補位
print data[data > 0]
#拷貝data
data2 = data.copy()
print data2
tag = ['a'] * 2 + ['b'] * 2 + ['c'] * 2
#在data2中增加TAG列用tag賦值
data2['TAG'] = tag
print data2
#打印TAG列中為a,c的行
print data2[data2.TAG.isin(['a','c'])]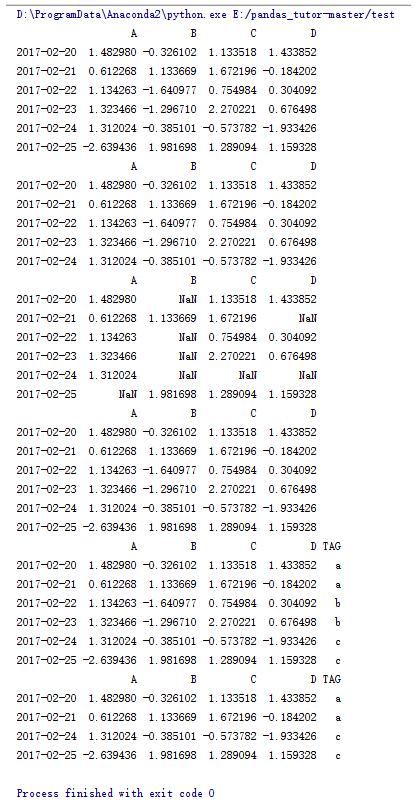
8.DataFrame的一些操作(6)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods=6)
data = pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
print data
#將第一行第一列元素賦值為100
data.iat[0,0] = 100
print data
#將A列元素用range(6)賦值
data.A = range(6)
print data
#將B列元素賦值為200
data.B = 200
print data
#將3,4列元素賦值為1000
data.iloc[:,2:5] = 1000
print data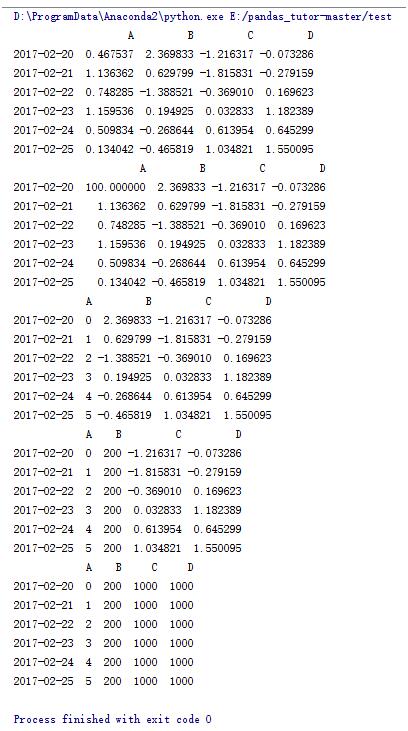
9.DataFrame的一些操作(7)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
#重定義索引,并添加E列
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
#將E列中的2,3行賦值為2
dfl.loc[dates[1:3],'E'] = 2
print dfl
#去掉存在NaN元素的行
print dfl.dropna()
#將NaN元素賦值為5
print dfl.fillna(5)
#判斷每個元素是否為NaN
print pd.isnull(dfl)
#求列平均值
print dfl.mean()
#對每列進行累加
print dfl.cumsum()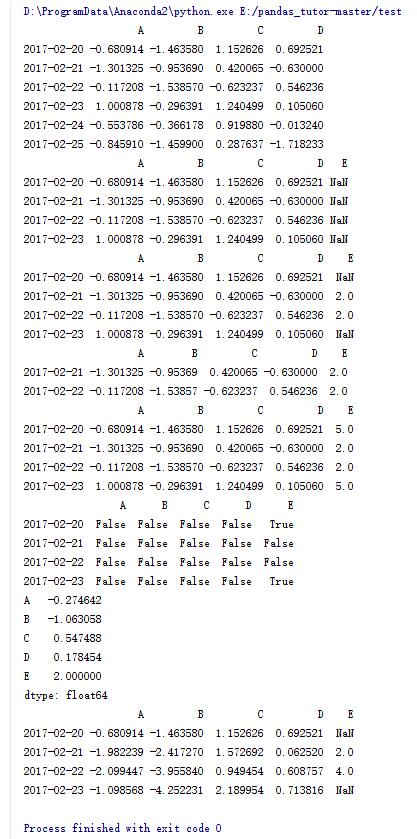
10.DataFrame的一些操作(8)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
dfl = df.reindex(index = dates[0:4],columns = list(df.columns)+['E'])
print dfl
#針對行求平均值
print dfl.mean(axis=1)
#生成序列并向右平移兩位
s = pd.Series([1,3,5,np.nan,6,8],index = dates).shift(2)
print s
#df與s做減法運算
print df.sub(s,axis = 'index')
#每列進行累加運算
print df.apply(np.cumsum)
#每列的最大值減去最小值
print df.apply(lambda x: x.max() - x.min())
11.DataFrame的一些操作(9)
import numpy as np
import pandas as pd
dates = pd.date_range('20170220',periods = 6)
df = pd.DataFrame(np.random.randn(6,4) , index = dates , columns = list('ABCD'))
print df
#定義一個函數
def _sum(x):
print(type(x))
return x.sum()
#apply函數可以接受一個函數作為參數
print df.apply(_sum)
s = pd.Series(np.random.randint(10,20,size = 15))
print s
#統計序列中每個元素出現的次數
print s.value_counts()
#返回出現次數最多的元素
print s.mode()
12.DataFrame的一些操作(10)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
print df
#合并函數
dfl = pd.concat([df.iloc[:3],df.iloc[3:7],df.iloc[7:]])
print dfl
#判斷兩個DataFrame中元素是否相等
print df == dfl
13.DataFrame的一些操作(11)
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(10,4) , columns = list('ABCD'))
print df
left = pd.DataFrame({'key':['foo','foo'],'lval':[1,2]})
right = pd.DataFrame({'key':['foo','foo'],'rval':[4,5]})
print left
print right
#通過key來合并數據
print pd.merge(left,right,on='key')
s = pd.Series(np.random.randint(1,5,size = 4),index = list('ABCD'))
print s
#通過序列添加一行
print df.append(s,ignore_index = True)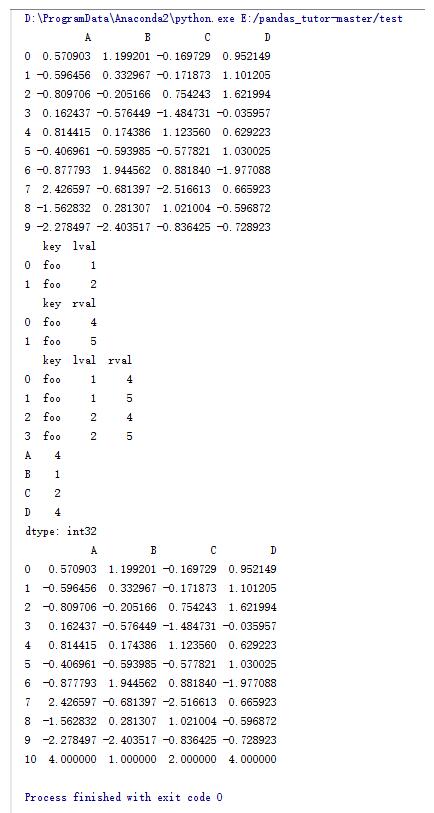
14.DataFrame的一些操作(12)
import numpy as np
import pandas as pd
df = pd.DataFrame({'A': ['foo','bar','foo','bar',
'foo','bar','foo','bar'],
'B': ['one','one','two','three',
'two','two','one','three'],
'C': np.random.randn(8),
'D': np.random.randn(8)})
print df
print
#根據A列的索引求和
print df.groupby('A').sum()
print
#先根據A列的索引,在根據B列的索引求和
print df.groupby(['A','B']).sum()
print
#先根據B列的索引,在根據A列的索引求和
print df.groupby(['B','A']).sum()
15.DataFrame的一些操作(13)
import pandas as pd import numpy as np #zip函數可以打包成一個個tuple tuples = list(zip(*[['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'], ['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']])) print tuples #生成一個多層索引 index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second']) print index print df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B']) print df print #將列索引變成行索引 print df.stack()
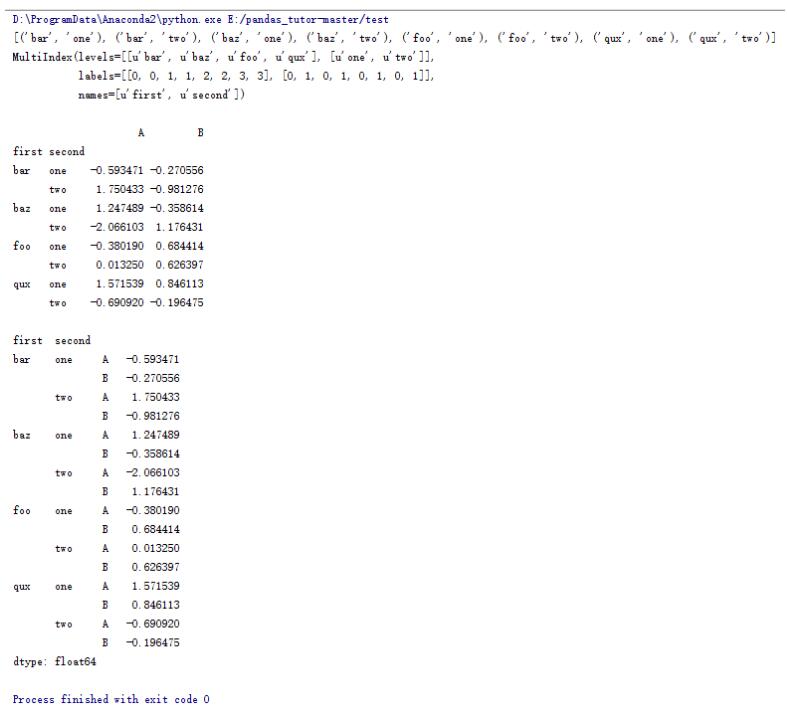
16.DataFrame的一些操作(14)
import pandas as pd import numpy as np tuples = list(zip(*[['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'], ['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']])) index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second']) df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B']) print df print stacked = df.stack() print stacked #將行索引轉換為列索引 print stacked.unstack() #轉換兩次 print stacked.unstack().unstack()

17.DataFrame的一些操作(15)
import pandas as pd
import numpy as np
df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3,
'B' : ['A', 'B', 'C'] * 4,
'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D' : np.random.randn(12),
'E' : np.random.randn(12)})
print df
#根據A,B索引為行,C的索引為列處理D的值
print pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
#感覺A列等于one為索引,根據C列組合的平均值
print df[df.A=='one'].groupby('C').mean()
18.時間序列(1)
import pandas as pd
import numpy as np
#創建一個以20170220為基準的以秒為單位的向前推進600個的時間序列
rng = pd.date_range('20170220', periods=600, freq='s')
print rng
#以時間序列為索引的序列
print pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
19.時間序列(2)
import pandas as pd
import numpy as np
rng = pd.date_range('20170220', periods=600, freq='s')
ts = pd.Series(np.random.randint(0, 500, len(rng)), index=rng)
#重采樣,以2分鐘為單位進行加和采樣
print ts.resample('2Min', how='sum')
#列出2011年1季度到2017年1季度
rng1 = pd.period_range('2011Q1','2017Q1',freq='Q')
print rng1
#轉換成時間戳形式
print rng1.to_timestamp()
#時間加減法
print pd.Timestamp('20170220') - pd.Timestamp('20170112')
print pd.Timestamp('20170220') + pd.Timedelta(days=12)
20.數據類別
import pandas as pd
import numpy as np
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'a', 'e']})
print df
#添加類別數據,以raw_grade的值為類別基礎
df["grade"] = df["raw_grade"].astype("category")
print df
#打印類別
print df["grade"].cat.categories
#更改類別
df["grade"].cat.categories = ["very good", "good", "very bad"]
print df
#根據grade的值排序
print df.sort_values(by='grade', ascending=True)
#根據grade排序顯示數量
print df.groupby("grade").size()
21.數據可視化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
ts = pd.Series(np.random.randn(1000), index=pd.date_range('20170220', periods=1000))
ts = ts.cumsum()
print ts
ts.plot()
plt.show()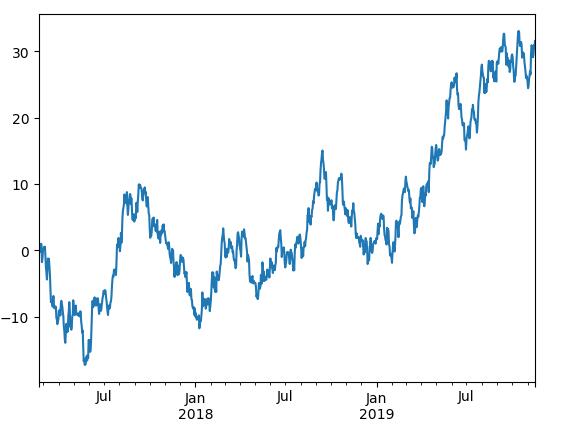
22.數據讀寫
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 4), columns=list('ABCD'))
#數據保存,相對路徑
df.to_csv('data.csv')
#數據讀取
print pd.read_csv('data.csv', index_col=0)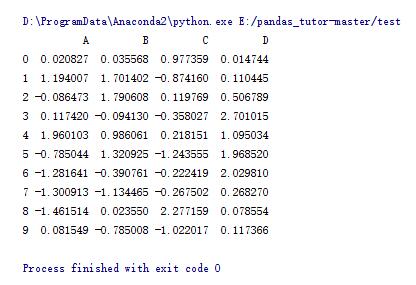
數據被保存到這個文件中:

打開看看:
到此,相信大家對“Python中pandas庫的基本操作方法”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





