溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下pandas之DataFrame行列數據篩選的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
一、對DataFrame的認知
DataFrame的本質是行(index)列(column)索引+多列數據。
為了簡化理解,我們不妨換個思路…
現實中,為了簡化對一件事物的描述,我們會選擇幾個特征。
例如,從(性別、身高、學歷、職業、愛好..)等角度去刻畫一個人,這些“角度”即為“特征”。
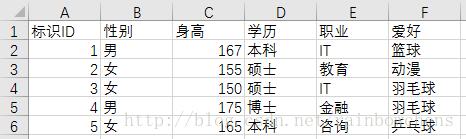
其中,不同的行表示不同的記錄;列代表特征,不同記錄因各個特征之間的差異而不同。
DataFrame默認索引是序號(0,1,2…),可以理解成位置索引。一般我們用id標識不同記錄,不會改變index。但為了理解不同特征(列)含義,我們往往會重新指定column。
一些簡易但不算嚴謹的理解是:
行列
行 – index – 記錄 (一般沿用默認索引)
列 – column – 特征 (自定義索引)
索引
默認索引 – 序號 – 位置 – 方便索引但理解不易
自定義索引 – 特征名稱 – 屬性 – 便于理解
二、對dataframe進行行列數據篩選
import pandas as pd,numpy as np
from pandas import DataFrame
df = DataFrame(np.arange(20).reshape((4,5)),column = list('abcde'))
1.df[]&df. 選取列數據
df.a df[[‘a','b']]
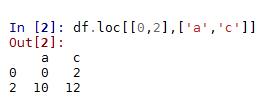
2.df.loc[[index],[colunm]] 通過標簽選擇數據
不對行進行篩選時,[index]處填 : (不能為空),即df.loc[:,'a']表示選取a列全部數據。
df.loc[0,'a'] df.loc[0:1,[‘a','b']] df.loc[[0,2],[‘a','c']]
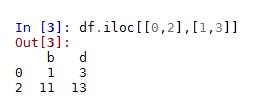
3.df.iloc[[index],[colunm]] 通過位置選擇數據
不對行進行篩選時,同df.loc[],即[index]處不能為空。
df.iloc[0,0] df.iloc[0:1,1:3] df.iloc[[0,2],[1,3]]
4.df.ix[[index],[column]] 通過標簽or位置選擇數據
df.ix[]混合了標簽和位置選擇。需要注意的是,[index]和[column]的框內需要指定同一類的選擇。
df.ix[[0:1],[‘a',3]]報錯
以上是“pandas之DataFrame行列數據篩選的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





