溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用python處理MS Word,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
1、簡單易用,與C/C++、Java、C# 等傳統語言相比,Python對代碼格式的要求沒有那么嚴格;2、Python屬于開源的,所有人都可以看到源代碼,并且可以被移植在許多平臺上使用;3、Python面向對象,能夠支持面向過程編程,也支持面向對象編程;4、Python是一種解釋性語言,Python寫的程序不需要編譯成二進制代碼,可以直接從源代碼運行程序;5、Python功能強大,擁有的模塊眾多,基本能夠實現所有的常見功能。
使用python工具讀寫MS Word文件(docx與doc文件),主要利用了python-docx包。本文給出一些常用的操作,并完成一個樣例,幫助大家快速入手。
安裝
pyhton處理docx文件需要使用python-docx 包,可以利用pip工具很方便的安裝,pip工具在python安裝路徑下的Scripts文件夾中
pip install python-docx
當然你也可以選擇使用easy_install或者手動方式進行安裝
寫入文件內容
此處我們直接給出一個樣例,根據自己的需要摘取有用的內容
#coding=utf-8
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
#打開文檔
document = Document()
#加入不同等級的標題
document.add_heading(u'MS WORD寫入測試',0)
document.add_heading(u'一級標題',1)
document.add_heading(u'二級標題',2)
#添加文本
paragraph = document.add_paragraph(u'我們在做文本測試!')
#設置字號
run = paragraph.add_run(u'設置字號、')
run.font.size = Pt(24)
#設置字體
run = paragraph.add_run('Set Font,')
run.font.name = 'Consolas'
#設置中文字體
run = paragraph.add_run(u'設置中文字體、')
run.font.name=u'宋體'
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), u'宋體')
#設置斜體
run = paragraph.add_run(u'斜體、')
run.italic = True
#設置粗體
run = paragraph.add_run(u'粗體').bold = True
#增加引用
document.add_paragraph('Intense quote', style='Intense Quote')
#增加無序列表
document.add_paragraph(
u'無序列表元素1', style='List Bullet'
)
document.add_paragraph(
u'無序列表元素2', style='List Bullet'
)
#增加有序列表
document.add_paragraph(
u'有序列表元素1', style='List Number'
)
document.add_paragraph(
u'有序列表元素2', style='List Number'
)
#增加圖像(此處用到圖像image.bmp,請自行添加腳本所在目錄中)
document.add_picture('image.bmp', width=Inches(1.25))
#增加表格
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Name'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
#再增加3行表格元素
for i in xrange(3):
row_cells = table.add_row().cells
row_cells[0].text = 'test'+str(i)
row_cells[1].text = str(i)
row_cells[2].text = 'desc'+str(i)
#增加分頁
document.add_page_break()
#保存文件
document.save(u'測試.docx')該段代碼生成的文檔樣式如下

注:有一個問題沒找到如何解決,即如何為表格設置邊框線。如果您知道,還請能夠指教。
讀取文件內容
#coding=utf-8
from docx import Document
#打開文檔
document = Document(u'測試.docx')
#讀取每段資料
l = [ paragraph.text.encode('gb2312') for paragraph in document.paragraphs];
#輸出并觀察結果,也可以通過其他手段處理文本即可
for i in l:
print i
#讀取表格材料,并輸出結果
tables = [table for table in document.tables];
for table in tables:
for row in table.rows:
for cell in row.cells:
print cell.text.encode('gb2312'),'\t',
print
print '\n'我們仍然使用剛才我們生成的文件,可以看到,輸出的結果為
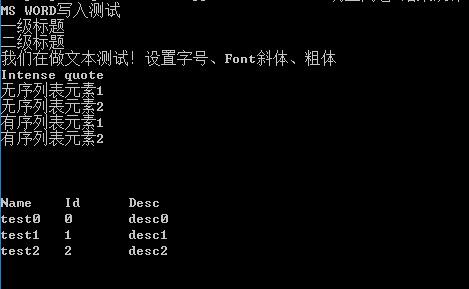
注意:此處我們使用gb2312編碼方式讀取,主要是保證中文的讀寫正確。一般情況下,使用的utf-8編碼方式。另外,python-docx主要處理docx文件,在加載doc文件時,會出現問題,如果有大量doc文件,建議先將doc文件批量轉換為docx文件,例如利用工具doc2doc
關于“如何使用python處理MS Word”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





