溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關python怎么刪除文本中行數標簽的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
1、簡單易用,與C/C++、Java、C# 等傳統語言相比,Python對代碼格式的要求沒有那么嚴格;2、Python屬于開源的,所有人都可以看到源代碼,并且可以被移植在許多平臺上使用;3、Python面向對象,能夠支持面向過程編程,也支持面向對象編程;4、Python是一種解釋性語言,Python寫的程序不需要編譯成二進制代碼,可以直接從源代碼運行程序;5、Python功能強大,擁有的模塊眾多,基本能夠實現所有的常見功能。
問題描述:
我們在網上下載或者復制別人代碼的時候經常會遇到下載的代碼中包含行數標簽的情況。如下圖:
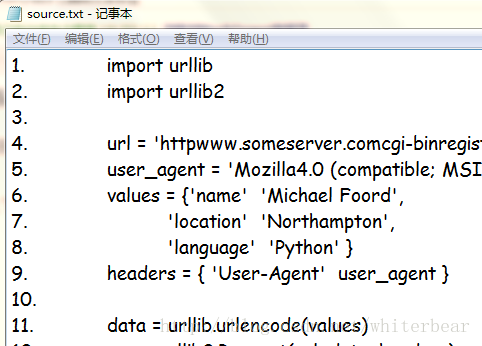
這些代碼中包含著行數如1.,2.等,如果我們想直接運行或者copy代碼需要自己手動的刪除這些標簽。既然學了python,我們寫一段腳本來處理它吧。
思路分析:
首先,我們逐行的讀取文本。
利用正則表達式,可以順利地匹配出所有的這些標簽以及后面跟隨的“\t”,正則表達式為:“\d+.\t”。
接著我們將匹配的結果在這一行中刪除它,使用string模塊的replace方法,將匹配的結果用‘'代替。
最后,我們保存每次刪除了行數標簽的結果行,然后將這些行寫入原文本。注意,以w的方式打開文本會刪除原文本內容。
代碼:
# -*- coding:utf-8 -*-
import re
import os
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
ls = os.linesep
label_regex = r'\d+.\t'
content = []
for line in open('source.txt', 'r'):
mm = re.search(label_regex, line)
if mm:
mm = mm.group()
content.append(line.replace(mm, '').rstrip())
else:
break
f = open('source.txt', 'w')
f.writelines(['%s%s' % (x,ls) for x in content])結果:
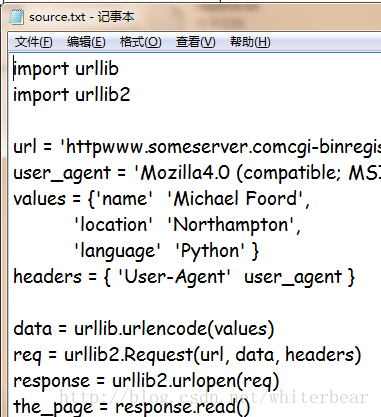
感謝各位的閱讀!關于“python怎么刪除文本中行數標簽”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





