溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、定義
正則表達式是對字符串操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個“規則字符串”,這個“規則字符串”用來表達對字符串的一種過濾邏輯。如果找到了符合這樣一種規則的字符串,我們就說匹配上了,否則匹配失敗。
二、匹配規則
1.語法規則

2.相關注解
a.反斜杠問題
假如你需要匹配文本中的字符"\",那么使用編程語言表示的正則表達式里將需要4個反斜杠"\\\\":前兩個和后兩個分別用于在編程語言里轉義成反斜杠,轉換成兩個反斜杠后再在正則表達式里轉義成一個反斜杠。其匹配過程如下:
| 字符 | 匹配過程 |
| \\\\abc | 為字符串實值取消反斜杠轉義 |
| \\abc | 為re.compile()取消反斜杠轉義 |
| \abc | 欲匹配的目標字符串 |
為了解決輸入四個“\”的麻煩,我們可以使用python里的原生字符串(raw string),即在字符串前面加上r。如下:
import re print(re.search(r"\\abc","123\\abc"))
從上面可知,使用原生字符串就省去了從字符串實值到re編譯器的字符串轉義過程,而編譯器編譯的時候仍然要轉義。
b.貪婪匹配與非貪婪匹配
貪婪匹配:正則表達式一般趨向于最大長度匹配,也就是所謂的貪婪匹配。如:
import re
print(re.match("ab.*c","abcdfghc"))
匹配的結果為整個字符串。而非貪婪匹配就是匹配到結果就好,最少地匹配字符。python默認是貪婪模式;在量詞后面直接加上一個問號?就是非貪婪模式。
import re
print(re.match("ab.*?c","abcdfghc"))
這樣匹配的結果就是“abc”。
三、模塊和函數
re模塊
compile()編譯語法規則
match() 從字符串開頭位置開始匹配
search() 從字符串任意位置匹配到第一個符合規則的字符串
findall 以列表形式返回所有匹配到的字符串
finditer 以迭代器形式返回所有匹配到的字符串
split() 拆分字符串
group() 獲取匹配到的字符串的分組信息
四、特殊構造的規則
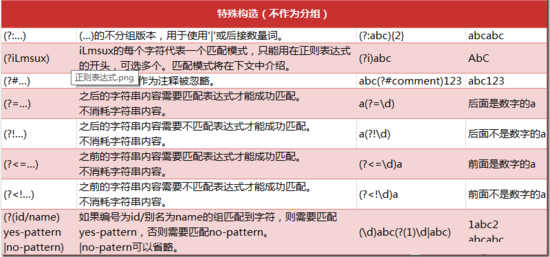
總結
以上所述是小編給大家介紹的python正則表達式之對號入座篇,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





