溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下Python爬蟲常用庫有哪些,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
Python常用庫的安裝
urllib、re 這兩個庫是Python的內置庫,直接使用方法import導入即可。
在python中輸入如下代碼:
import urllib
import urllib.request
response=urllib.request.urlopen("http://www.baidu.com")
print(response)返回結果為HTTPResponse的對象:
<http.client.HTTPResponse object at 0x000001929C7525F8>
正則表達式模塊
import re
該庫為python自帶的庫,直接運行不報錯,證明該庫正確安裝。
requests這個庫是請求的庫
我們需要使用執行文件pip3來進行安裝。文件處于C:\Python36\Scripts下,我們可以先將此路徑設為環境變量。在命令行中輸入pip3 install requests進行安裝。安裝完成后進行驗證
>>> import requests
>>> requests.get('http://www.baidu.com')
<Response [200]>selenium實際上是用來瀏覽器的一個庫
做爬蟲時可能會碰到使用JS渲染的網頁,使用requests來請求時,可能無法正常獲取內容,我們使用selenium可以驅動瀏覽器獲得渲染后的頁面。也是使用pip3 install selenium安裝。進行驗證
>>> import selenium
>>> from selenium import webdriver
>>> driver = webdriver.Chrome()
DevTools listening on ws://127.0.0.1:60980/devtools/browser/7c2cf211-1a8e-41ea-8e4a-c97356c98910
>>> driver.get('http://www.baidu.com')上述命令可以直接打開chrome瀏覽器,并且打開百度。但是,在這之前我們必須安裝一個chromedriver,并且安裝googlchrome瀏覽器,可自行去官網下載。當我們安裝完畢后再運行這些測試代碼可能依舊會出現一閃而退的情況,那么問題出在,chrome和chromdriver的版本不兼容,可以在官網下載chrome更高的版本,或者chromedriver更低的版本,但是只要都是最高版本就沒問題。
如何查看本機的chrome的版本,具體方法如下:

chromedriver的下載地址如下:
http://chromedriver.storage.googleapis.com/index.html
chromedriver解壓后放到Python或者其他配置了環境變量的目錄下。
phantomjs是一個無界面瀏覽器,在后臺運行
可在官網自行下載。并且需要將phantomjs.exe 的所在目錄設為環境變量。測試代碼
>>> from selenium import webdriver
>>> driver = webdriver.PhantomJS()
>>> driver.get('http://www.baidu.com')
>>> driver.page_source
'<!DOCTYPE html><!--STATUS OK--><html><head>\nlxml
使用pip3 install lxml安裝
beautifulsoup是一個網絡解析庫,依賴于lxml庫
使用pip3安裝。必須安裝pip3 install beautifulsoup4,因為beautifulsoup已經停止維護了。安裝驗證
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup('<html></html>','lxml')
>>>pyquery也是網頁解析庫
較bs4更加方便,語法和Jquery無異。也是使用pip3 安裝
>>> from pyquery import PyQuery as pq #將其重命名
>>> doc = pq('<html></html>')
>>> doc = pq('<html>hello world</html>')
>>> result = doc('html').text()
>>> result
'hello world'pymysql是一個操作mysql數據庫的庫
使用pip3 安裝
>>> import pymysql
>>> conn = pymysql.connect(host='localhost',user='root',password = '123456',port=3306,db='mysql')
>>> cursor = conn.cursor()
>>> cursor.execute('select * from db')
0pymongo操作數據庫MongoDB的庫
需要開啟MongoDB服務,在計算機管理當中的服務尋找。也是使用pip3安裝
>>> import pymongo
>>> client = pymongo.MongoClient('localhost')
>>> db = client['newtestdb']
>>> db['table'].insert({'name':'tom'})
ObjectId('5b868ee4c4d17a0b2466f748')
>>> db['table'].find_one({'name':'tom'})
{'_id': ObjectId('5b868ee4c4d17a0b2466f748'), 'name': 'tom'}
>>> #完成了單條數據的查詢使用pip3 install redis安裝
>>> import redis
>>> r = redis.Redis ('localhost',6379)
>>> r.set('name','tom')
True
>>> r.get('name')
b'tom'
>>> #是一個byte型數據類型flask做代理時可能會用到
詳細內容可以在flask官網查看flask文檔
使用pip3 安裝pip3 install flask
django是一個web服務器框架
提供了一個完整的后臺管理,引擎、接口等,可以使用它做一個完整的網站。可在django的官網查看文檔。使用pip3 install django安裝
jupyter 可以理解為一個記事本
運行網頁端,可以進行寫代碼,調試,運行。在官網可以下載jupyter,也可以用pip3 安裝,相關庫非常多,安裝比較久。安裝后可以在命令行直接運行jupyter notebook,因為此文件在scrips目錄下。
C:\Users\dell>jupyter notebook
[I 20:32:37.552 NotebookApp] The port 8888 is already in use, trying another port.
[I 20:32:37.703 NotebookApp] Serving notebooks from local directory: C:\Users\dell
可以在選項 new 中建立新python3文件,并且可以編寫代碼。
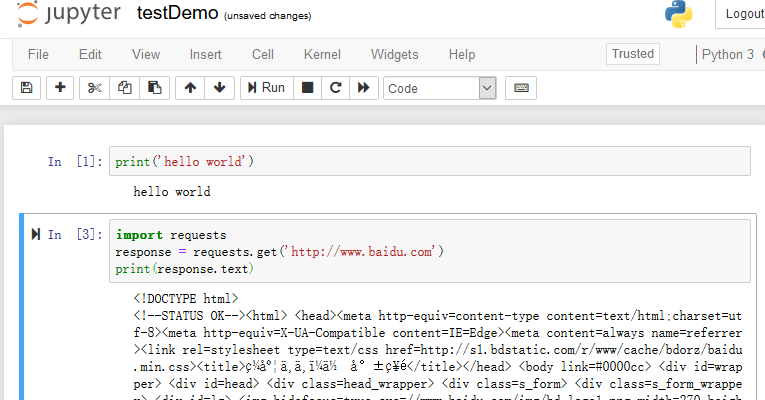
默認的文件名為unite,此處將其改為testDemo,使用快捷鍵ctrl+回車 運行,按鍵B跳轉至新的編輯行。
以上是“Python爬蟲常用庫有哪些”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





