溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下如何使用Python機器學習降低靜態日志噪聲,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
1、云計算,典型應用OpenStack。2、WEB前端開發,眾多大型網站均為Python開發。3.人工智能應用,基于大數據分析和深度學習而發展出來的人工智能本質上已經無法離開python。4、系統運維工程項目,自動化運維的標配就是python+Django/flask。5、金融理財分析,量化交易,金融分析。6、大數據分析。
持續集成(CI)作業可以產生大量的數據。當作業失敗時,找出了什么問題可能是一個繁瑣的過程,需要對日志進行調查以發現根本原因-這通常是在作業總輸出的一小部分中發現的。為了更容易地將最相關的數據從其他數據中分離出來,日志還原機器學習模型使用以前成功的作業運行來訓練,以從失敗的運行日志中提取異常。
此原則也可應用于其他用例,例如,從期刊或其他系統范圍的常規日志文件。
利用機器學習降低噪聲
一個典型的日志文件包含許多名義事件(“基線”)以及一些與開發人員相關的異常。基線可能包含難以檢測和刪除的隨機元素,如時間戳或唯一標識符。要刪除基線事件,我們可以使用k最近鄰模式識別算法 (k-NN)。
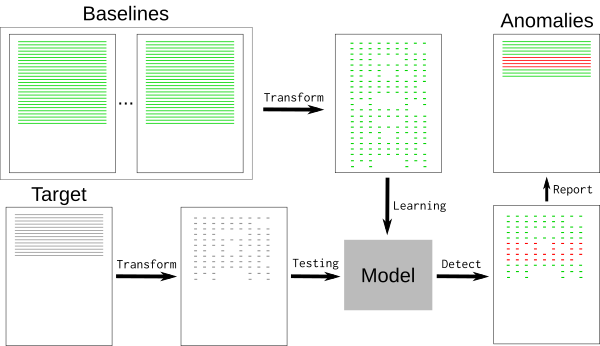
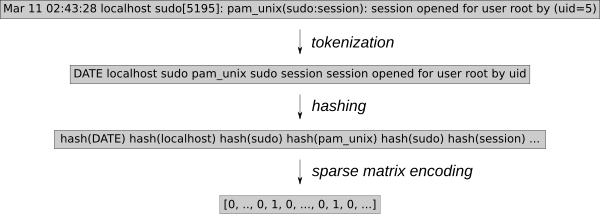
的日志事件必須轉換為數值。k-NN回歸。使用通用特征提取工具HashingVectorizer允許將該進程應用于任何類型的日志。它對每個單詞進行散列,并在稀疏矩陣中對每個事件進行編碼。為了進一步減少搜索空間,令牌化將刪除已知的隨機單詞,例如日期或IP地址。
一旦模型被訓練,k-NN搜索告訴我們每個新事件與基線之間的距離。

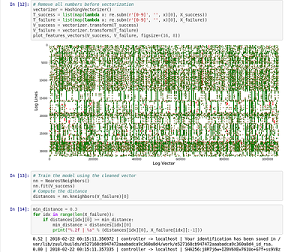
Jupyter notebook演示了稀疏矩陣向量的過程,并繪制了稀疏矩陣向量圖。
介紹LOGPREIN
LogReallyPython軟件透明地實現了這個過程。的最初目標是協助祖爾CI使用構建數據庫進行作業失敗分析,現在將其集成到軟件廠發展鍛造的工作日志過程。
最簡單的是,LogReduce比較文件或目錄,并刪除類似的行。Log冷水為每個源文件構建一個模型,并使用以下語法輸出距離超過定義閾值的任何目標行:距離文件名:行號:行內容.
$ logreduce varlogauditaudit.log.1 varlogauditaudit.log INFO logreduce.Classifier - Training took 21.982s at 0.364MBs 1.314kls 8.000 MB - 28.884 kilo-lines 0.244 audit.log:19963: =USER_AUTH ="root" ="/usr/bin/su" hostname=managesf.sftests.com INFO logreduce.Classifier - Testing took 18.297s at 0.306MBs 1.094kls 5.607 MB - 20.015 kilo-lines 99.99 reduction from 20015 lines to
更高級的LogReduce使用可以將模型離線訓練成可重用的模型。基線的許多變體可以用來適應k-NN搜索樹
$ logreduce dir-train audit.clf varlogauditaudit.log. INFO logreduce.Classifier - Training took 80.883s at 0.396MBs 1.397kls 32.001 MB - 112.977 kilo-lines DEBUG logreduce.Classifier - audit.clf: written $ logreduce dir-run audit.clf varlogauditaudit.log
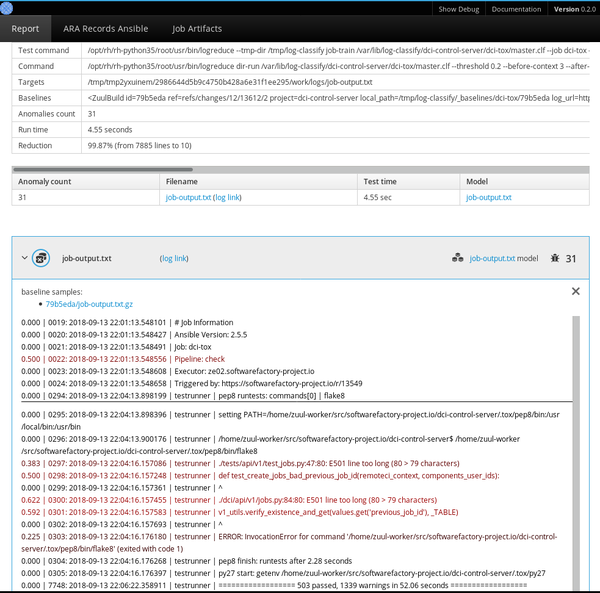
LogReduce還實現了接口,以發現日志時間范圍(天/周/月)和Zuul CI作業構建歷史記錄的基線。它還可以生成HTML報告,在一個簡單的接口中發現多個文件中的組異常。
管理基線
使用的關鍵k-神經網絡回歸異常檢測是有一個已知的良好基線的數據庫,該模型用于檢測偏離過遠的線。該方法依賴于包含所有標稱事件的基線,因為基線中沒有發現的任何事件都將被報告為異常。
Ci工作是我們的主要目標。k-NN回歸,因為作業輸出通常是確定性的,以前的運行可以自動用作基線。Log還原功能可以將Zuul作業角色用作失敗的作業發布任務的一部分,以便發布簡明的報告(而不是完整的作業日志)。這一原則可適用于其他情況,只要可以事先建立基線。例如,一個標稱系統的SOS報告可用于查找有缺陷的部署中的問題。
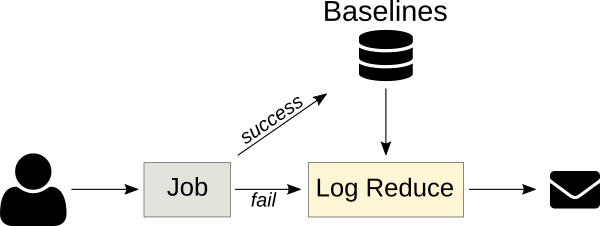
異常分類服務
下一個版本的Logreduce引入了一種服務器模式,用于將日志處理卸載到外部服務,在該服務中可以進一步分析報表。它還支持導入現有的報告和請求來分析Zuul構建。服務運行異步地進行分析,并提供一個Web界面來調整分數和刪除假陽性。
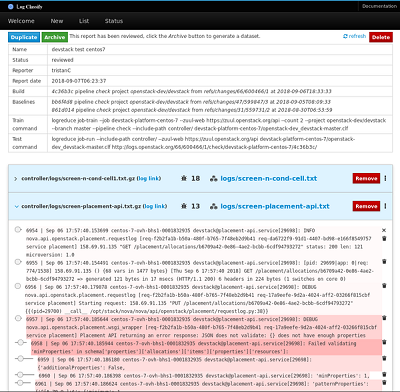
評審報告可以作為獨立的數據集存檔,目標日志文件和記錄在平面JSON文件中的異常行的分數。
項目路線圖
LogReduce已經被有效地使用了,但是有很多改進工具的機會。今后的計劃包括:
管理日志文件中發現的許多帶注釋的異常,并生成公共域數據集,以便進一步研究。日志文件中的異常檢測是一個具有挑戰性的主題,擁有一個通用的數據集來測試新的模型將有助于確定新的解決方案。
使用模型重用帶注釋的異常,以細化所報告的距離。例如,當用戶通過將其距離設置為零將行標記為假陽性時,該模型可以減少這些行在未來報告中的得分。
指紋歸檔異常以檢測新的報告何時包含已知的異常。因此,服務可以通知用戶作業遇到了已知的問題,而不是報告異常的內容。解決問題后,服務可以自動重新啟動作業。
支持更多的目標基線發現接口,如SOS報告、Jenkins構建、Travis CI等。
看完了這篇文章,相信你對“如何使用Python機器學習降低靜態日志噪聲”有了一定的了解,如果想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





