溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
PYTHON Pandas批量讀取csv文件到DATAFRAME

首先使用glob.glob獲得文件路徑。然后定義一個列表,讀取文件后再使用concat合并讀取到的數據。
#讀取數據 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f in file: dl.append(pd.read_excel(f,header=[0,1],index_col=None)) df=pd.concat(dl)
下面看下Python使用pandas處理CSV文件的方法
Python中有許多方便的庫可以用來進行數據處理,尤其是Numpy和Pandas,再搭配matplot畫圖專用模塊,功能十分強大。
CSV(Comma-Separated Values)格式的文件是指以純文本形式存儲的表格數據,這意味著不能簡單的使用Excel表格工具進行處理,而且Excel表格處理的數據量十分有限,而使用Pandas來處理數據量巨大的CSV文件就容易的多了。
我用到的是自己用其他硬件工具抓取得數據,硬件環境是在Linux平臺上搭建的,當時數據是在運行腳本后直接輸出在terminal里的,數據量十分龐大,為了保存獲得的數據,在Linux下使用了數據流重定向,把數據全部保存到了文本文件中,形成了一個本地csv文件。
Pandas讀取本地CSV文件并設置Dataframe(數據格式)
import pandas as pd
import numpy as np
df=pd.read_csv('filename',header=None,sep=' ') #filename可以直接從盤符開始,標明每一級的文件夾直到csv文件,header=None表示頭部為空,sep=' '表示數據間使用空格作為分隔符,如果分隔符是逗號,只需換成 ‘,'即可。
print df.head()
print df.tail()
#作為示例,輸出CSV文件的前5行和最后5行,這是pandas默認的輸出5行,可以根據需要自己設定輸出幾行的值
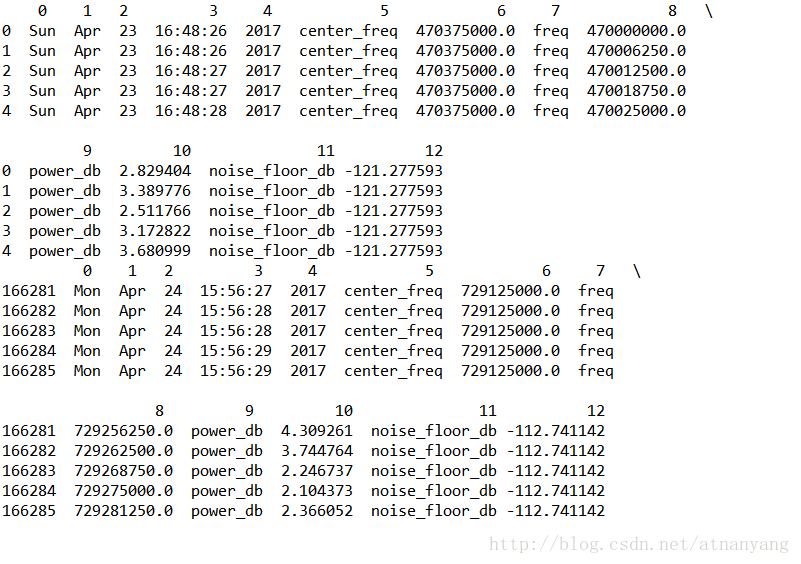
圖片中顯示了我本地數據的前5行與最后5行,最前面一列沒有標號的是行號,數據一共有13列,標號從0到12,一行顯示不完全,在第9列以后換了行,并且用反斜杠“\”標注了出來。
2017年4月28日更新
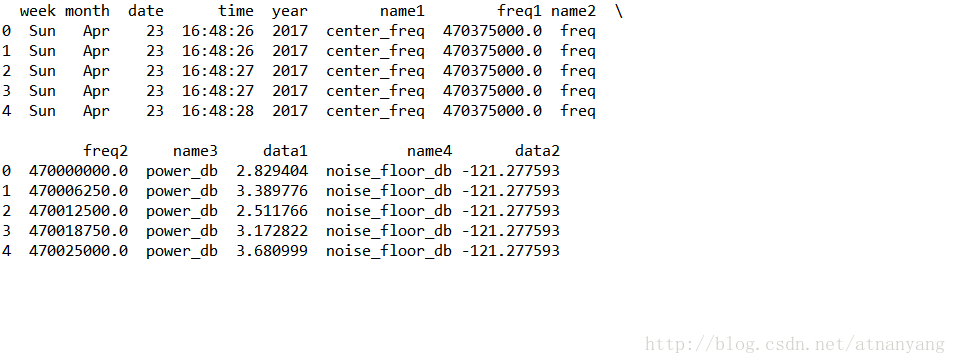
使用pandas直接讀取本地的csv文件后,csv文件的列索引默認為從0開始的數字,重定義列索引的語句如下:
import pandas as pd
import numpy as np
df=pd.read_csv('filename',header=None,sep=' ',names=["week",'month','date','time','year','name1','freq1','name2','freq2','name3','data1','name4','data2'])
print df1234
此時打印出的文件信息如下,列索引已經被重命名:
總結
以上所述是小編給大家介紹的Python Pandas批量讀取csv文件到dataframe的方法,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





