溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文將和大家分享一些從互聯網上爬取語料的經驗。
0x1 工具準備
工欲善其事必先利其器,爬取語料的根基便是基于python。
我們基于python3進行開發,主要使用以下幾個模塊:requests、lxml、json。
簡單介紹一個各模塊的功能
01|requests
requests是一個Python第三方庫,處理URL資源特別方便。它的官方文檔上寫著大大口號:HTTP for Humans(為人類使用HTTP而生)。相比python自帶的urllib使用體驗,筆者認為requests的使用體驗比urllib高了一個數量級。
我們簡單的比較一下:
urllib:
import urllib2
import urllib
URL_GET = "https://api.douban.com/v2/event/list"
#構建請求參數
params = urllib.urlencode({'loc':'108288','day_type':'weekend','type':'exhibition'})
#發送請求
response = urllib2.urlopen('?'.join([URL_GET,'%s'])%params)
#Response Headers
print(response.info())
#Response Code
print(response.getcode())
#Response Body
print(response.read())
requests:
import requests
URL_GET = "https://api.douban.com/v2/event/list"
#構建請求參數
params = {'loc':'108288','day_type':'weekend','type':'exhibition'}
#發送請求
response = requests.get(URL_GET,params=params)
#Response Headers
print(response.headers)
#Response Code
print(response.status_code)
#Response Body
print(response.text)
我們可以發現,這兩種庫還是有一些區別的:
1. 參數的構建:urllib需要對參數進行urlencode編碼處理,比較麻煩;requests無需額外編碼處理,十分簡潔。
2. 請求發送:urllib需要額外對url參數進行構造,變為符合要求的形式;requests則簡明很多,直接get對應鏈接與參數。
3. 連接方式:看一下返回數據的頭信息的“connection”,使用urllib庫時,"connection":"close",說明每次請求結束關掉socket通道,而使用requests庫使用了urllib3,多次請求重復使用一個socket,"connection":"keep-alive",說明多次請求使用一個連接,消耗更少的資源
4. 編碼方式:requests庫的編碼方式Accept-Encoding更全,在此不做舉例
綜上所訴,使用requests更為簡明、易懂,極大的方便我們開發。
02|lxml
BeautifulSoup是一個庫,而XPath是一種技術,python中最常用的XPath庫是lxml。
當我們拿到requests返回的頁面后,我們怎么拿到想要的數據呢?這個時候祭出lxml這強大的HTML/XML解析工具。python從不缺解析庫,那么我們為什么要在眾多庫里選擇lxml呢?我們選擇另一款出名的HTML解析庫BeautifulSoup來進行對比。
我們簡單的比較一下:
BeautifulSoup:
from bs4 import BeautifulSoup #導入庫
# 假設html是需要被解析的html
#將html傳入BeautifulSoup 的構造方法,得到一個文檔的對象
soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
#查找所有的h5標簽
links = soup.find_all("h5")
lxml:
from lxml import etree
# 假設html是需要被解析的html
#將html傳入etree 的構造方法,得到一個文檔的對象
root = etree.HTML(html)
#查找所有的h5標簽
links = root.xpath("http://h5")
我們可以發現,這兩種庫還是有一些區別的:
1. 解析html: BeautifulSoup的解析方式和JQ的寫法類似,API非常人性化,支持css選擇器;lxml的語法有一定的學習成本
2. 性能:BeautifulSoup是基于DOM的,會載入整個文檔,解析整個DOM樹,因此時間和內存開銷都會大很多;而lxml只會局部遍歷,另外lxml是用c寫的,而BeautifulSoup是用python寫的,明顯的性能上lxml>>BeautifulSoup。
綜上所訴,使用BeautifulSoup更為簡明、易用,lxml雖然有一定學習成本,但總體也很簡明易懂,最重要的是它基于C編寫,速度快很多,對于筆者這種強迫癥,自然而然就選lxml啦。
03|json
python自帶json庫,對于基礎的json的處理,自帶庫完全足夠。但是如果你想更偷懶,可以使用第三方json庫,常見的有demjson、simplejson。
這兩種庫,無論是import模塊速度,還是編碼、解碼速度,都是simplejson更勝一籌,再加上兼容性 simplejson 更好。所以大家如果想使用方庫,可以使用simplejson。
0x2 確定語料源
將武器準備好之后,接下來就需要確定爬取方向。
以電競類語料為例,現在我們要爬電競類相關語料。大家熟悉的電競平臺有企鵝電競、企鵝電競和企鵝電競(斜眼),所以我們以企鵝電競上直播的游戲作為數據源進行爬取。
我們登陸企鵝電競官網,進入游戲列表頁,可以發現頁面上有很多游戲,通過人工去寫這些游戲名收益明顯不高,于是我們就開始我們爬蟲的第一步:游戲列表爬取。
import requests
from lxml import etree
# 更新游戲列表
def _updateGameList():
# 發送HTTP請求時的HEAD信息,用于偽裝為瀏覽器
heads = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
# 需要爬取的游戲列表頁
url = 'https://egame.qq.com/gamelist'
# 不壓縮html,最大鏈接時間為10妙
res = requests.get(url, headers=heads, verify=False, timeout=10)
# 為防止出錯,編碼utf-8
res.encoding = 'utf-8'
# 將html構建為Xpath模式
root = etree.HTML(res.content)
# 使用Xpath語法,獲取游戲名
gameList = root.xpath("http://ul[@class='livelist-mod']//li//p//text()")
# 輸出爬到的游戲名
print(gameList)
當我們拿到這幾十個游戲名后,下一步就是對這幾十款游戲進行語料爬取,這時候問題就來了,我們要從哪個網站來爬這幾十個游戲的攻略呢,taptap?多玩?17173?在對這幾個網站進行分析后,發現這些網站僅有一些熱門游戲的文章語料,一些冷門或者低熱度的游戲,例如“靈魂籌碼”、“奇跡:覺醒”、“死神來了”等,很難在這些網站上找到大量文章語料,如圖所示:
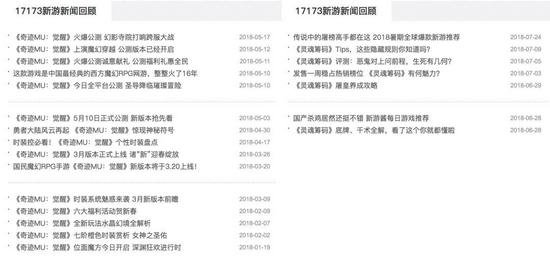
我們可以發現,“ 奇跡:覺醒”、“靈魂籌碼”的文章語料特別少,數量上不符合我們的要求。 那么有沒有一個比較通用的資源站,它擁有著無比豐富的文章語料,可以滿足我們的需求。
其實靜下心來想想,這個資源站我們天天都有用到,那就是百度。我們在百度新聞搜索相關游戲,拿到搜索結果列表,這些列表的鏈接的網頁內容幾乎都與搜索結果強相關,這樣我們數據源不夠豐富的問題便輕松解決了。但是此時出現了一個新的問題,并且是一個比較難解決的問題——如何抓取到任意網頁的文章內容?
因為不同的網站都有不同的頁面結構,我們無法與預知將會爬到哪個網站的數據,并且我們也不可能針對每一個網站都去寫一套爬蟲,那樣的工作量簡直難以想象!但是我們也不能簡單粗暴的將頁面中的所有文字都爬下來,用那樣的語料來進行訓練無疑是噩夢!
經過與各個網站斗智斗勇、查詢資料與思索之后,終于找到一條比較通用的方案,下面為大家講一講筆者的思路。
0x3 任意網站的文章語料爬取
01|提取方法
1)基于Dom樹正文提取
2)基于網頁分割找正文塊
3)基于標記窗的正文提取
4)基于數據挖掘或機器學習
5)基于行塊分布函數正文提取
02|提取原理
大家看到這幾種是不是都有點疑惑了,它們到底是怎么提取的呢?讓筆者慢慢道來。
1)基于Dom樹的正文提取:
這一種方法主要是通過比較規范的HTML建立Dom樹,然后地柜遍歷Dom,比較并識別各種非正文信息,包括廣告、鏈接和非重要節點信息,將非正文信息抽離之后,余下來的自然就是正文信息。
但是這種方法有兩個問題
① 特別依賴于HTML的良好結構,如果我們爬取到一個不按W3c規范的編寫的網頁時,這種方法便不是很適用。
② 樹的建立和遍歷時間復雜度、空間復雜度都較高,樹的遍歷方法也因HTML標簽會有不同的差異。
2) 基于網頁分割找正文塊 :
這一種方法是利用HTML標簽中的分割線以及一些視覺信息(如文字顏色、字體大小、文字信息等)。
這種方法存在一個問題:
① 不同的網站HTML風格迥異,分割沒有辦法統一,無法保證通用性。
3) 基于標記窗的正文提取:
先科普一個概念——標記窗,我們將兩個標簽以及其內部包含的文本合在一起成為一個標記窗(比如 <h2>我是h2</h2> 中的“我是h2”就是標記窗內容),取出標記窗的文字。
這種方法先取文章標題、HTML中所有的標記窗,在對其進行分詞。然后計算標題的序列與標記窗文本序列的詞語距離L,如果L小于一個閾值,則認為此標記窗內的文本是正文。
這種方法雖然看上去挺好,但其實也是存在問題的:
① 需要對頁面中的所有文本進行分詞,效率不高。
② 詞語距離的閾值難以確定,不同的文章擁有不同的閾值。
4)基于數據挖掘或機器學習
使用大數據進行訓練,讓機器提取主文本。
這種方法肯定是極好的,但是它需要先有html與正文數據,然后進行訓練。我們在此不進行探討。
5)基于行塊分布函數正文提取
對于任意一個網頁,它的正文和標簽總是雜糅在一起。此方法的核心有亮點:① 正文區的密度;② 行塊的長度;一個網頁的正文區域肯定是文字信息分布最密集的區域之一,這個區域可能最大(評論信息長、正文較短),所以同時引進行塊長度進行判斷。
實現思路:
① 我們先將HTML去標簽,只留所有正文,同時留下標簽取出后的所有空白位置信息,我們稱其為Ctext;
② 對每一個Ctext取周圍k行(k<5),合起來稱為Cblock;
③ 對Cblock去掉所有空白符,其文字總長度稱為Clen;
④ 以Ctext為橫坐標軸,以各行的Clen為縱軸,建立坐標系。
以這個網頁為例: http://www.gov.cn/ldhd/2009-11/08/content_1459564.htm 該網頁的正文區域為145行至182行。
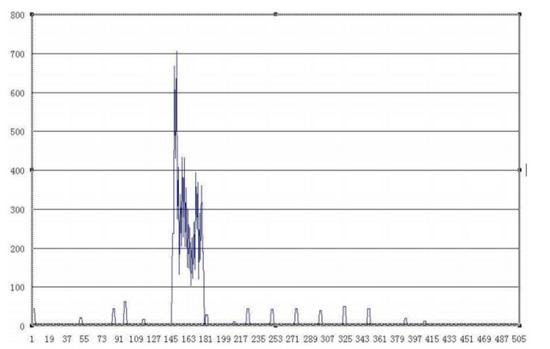
由上圖可知,正確的文本區域全都是分布函數圖上含有最值且連續的一個區域,這個區域往往含有一個驟升點和一個驟降點。因此,網頁正文抽取問題轉化為了求行塊分布函數上的驟升點和驟降點兩個邊界點,這兩個邊界點所含的區域包含了當前網頁的行塊長度最大值并且是連續的。
經過大量實驗,證明此方法對于中文網頁的正文提取有較高的準確度,此算法的優點在于,行塊函數不依賴與HTML代碼,與HTML標簽無關,實現簡單,準確率較高。
主要邏輯代碼如下:
# 假設content為已經拿到的html
# Ctext取周圍k行(k<5),定為3
blocksWidth = 3
# 每一個Cblock的長度
Ctext_len = []
# Ctext
lines = content.split('n')
# 去空格
for i in range(len(lines)):
if lines[i] == ' ' or lines[i] == 'n':
lines[i] = ''
# 計算縱坐標,每一個Ctext的長度
for i in range(0, len(lines) - blocksWidth):
wordsNum = 0
for j in range(i, i + blocksWidth):
lines[j] = lines[j].replace("\s", "")
wordsNum += len(lines[j])
Ctext_len.append(wordsNum)
# 開始標識
start = -1
# 結束標識
end = -1
# 是否開始標識
boolstart = False
# 是否結束標識
boolend = False
# 行塊的長度閾值
max_text_len = 88
# 文章主內容
main_text = []
# 沒有分割出Ctext
if len(Ctext_len) < 3:
return '沒有正文'
for i in range(len(Ctext_len) - 3):
# 如果高于這個閾值
if(Ctext_len[i] > max_text_len and (not boolstart)):
# Cblock下面3個都不為0,認為是正文
if (Ctext_len[i + 1] != 0 or Ctext_len[i + 2] != 0 or Ctext_len[i + 3] != 0):
boolstart = True
start = i
continue
if (boolstart):
# Cblock下面3個中有0,則結束
if (Ctext_len[i] == 0 or Ctext_len[i + 1] == 0):
end = i
boolend = True
tmp = []
# 判斷下面還有沒有正文
if(boolend):
for ii in range(start, end + 1):
if(len(lines[ii]) < 5):
continue
tmp.append(lines[ii] + "n")
str = "".join(list(tmp))
# 去掉版權信息
if ("Copyright" in str or "版權所有" in str):
continue
main_text.append(str)
boolstart = boolend = False
# 返回主內容
result = "".join(list(main_text))
0x4 結語
至此我們就可以獲取任意內容的文章語料了,但這僅僅是開始,獲取到了這些語料后我們還需要在一次進行清洗、分詞、詞性標注等,才能獲得真正可以使用的語料。
總結
以上所述是小編給大家介紹的用python3教你任意Html主內容提取功能,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





