溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如果你在爬蟲過程中有遇到“您的請求太過頻繁,請稍后再試”,或者說代碼完全正確,可是爬蟲過程中突然就訪問不了,那么恭喜你,你的爬蟲被對方識破了,輕則給予友好提示警告,嚴重的可能會對你的ip進行封禁,所以代理ip那就尤為重要了。今天我們就來談一下代理IP,去解決爬蟲被封的問題。
網上有許多代理ip,免費的、付費的。大多數公司爬蟲會買這些專業版,對于普通人來說,免費的基本滿足我們需要了,不過免費有一個弊端,時效性不強,不穩定,所以我們就需要對采集的ip進行一個簡單的驗證。
1.目標采集
本文主要針對西刺代理,這個網站很早之前用過,不過那個時候它還提供免費的api,現在api暫不提供了,我們就寫個簡單的爬蟲去采集。
打開西刺代理,有幾個頁面,果斷選擇高匿代理。
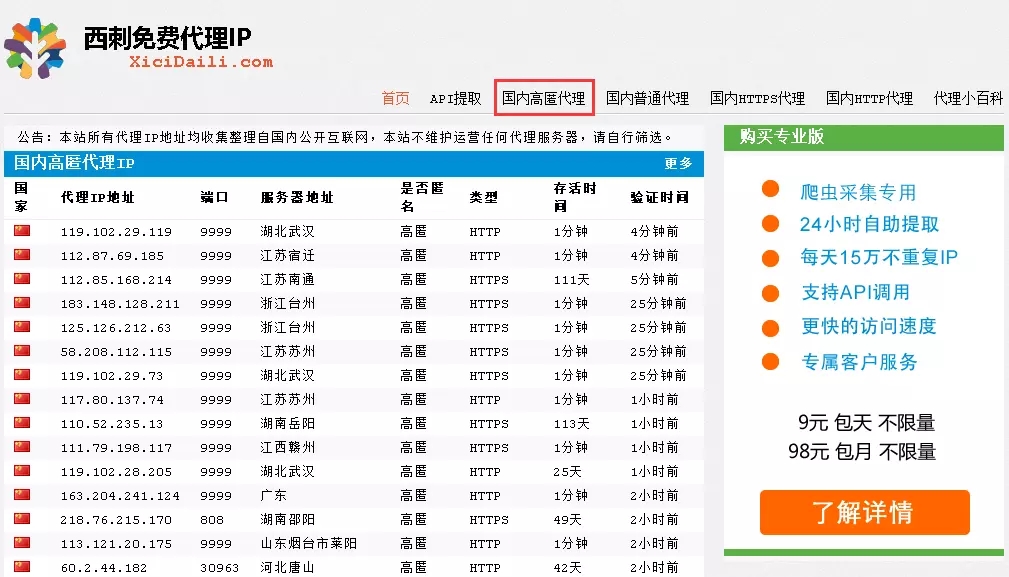
Chrome瀏覽器右鍵檢查查看network,不難發現,每個ip地址都在td標簽中,對于我們來說就簡單許多了,初步的想法就是獲取所有的ip,然后校驗可用性,不可用就剔除。

定義匹配規則
import re ip_compile = re.compile(r'<td>(\d+\.\d+\.\d+\.\d+)</td>') # 匹配IP port_compile = re.compile(r'<td>(\d+)</td>') # 匹配端口
2.校驗 這里我使用淘寶ip地址庫檢驗可用性
2.1、關于淘寶IP地址庫
目前提供的服務包括:
我們的優勢:
2.2、接口說明
請求接口(GET):
ip.taobao.com/service/get…
例:http://ip.taobao.com/service/getIpInfo2.php?ip=111.177.181.44
響應信息:
(json格式的)國家 、省(自治區或直轄市)、市(縣)、運營商
返回數據格式:
{"code":0,"data":{"ip":"210.75.225.254","country":"\u4e2d\u56fd","area":"\u534e\u5317",
"region":"\u5317\u4eac\u5e02","city":"\u5317\u4eac\u5e02","county":"","isp":"\u7535\u4fe1",
"country_id":"86","area_id":"100000","region_id":"110000","city_id":"110000",
"county_id":"-1","isp_id":"100017"}}
其中code的值的含義為,0:成功,1:失敗。
注意:為了保障服務正常運行,每個用戶的訪問頻率需小于10qps。
我們先通過瀏覽器測試一下
輸入地址http://ip.taobao.com/service/getIpInfo2.php?ip=111.177.181.44

再次輸入一個地址http://ip.taobao.com/service/getIpInfo2.php?ip=112.85.168.98
代碼操作
import requests
check_api = "http://ip.taobao.com/service/getIpInfo2.php?ip="
api = check_api + ip
try:
response = requests.get(url=api, headers=api_headers, timeout=2)
print("ip:%s 可用" % ip)
except Exception as e:
print("此ip %s 已失效:%s" % (ip, e))
3.代碼
代碼中加入了異常處理,其實自己手寫的demo寫不寫異常處理都可以,但是為了方便其他人調試,建議在可能出現異常的地方加入異常處理。
import requests
import re
import random
from bs4 import BeautifulSoup
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36",
"Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 45.0.2454.101Safari / 537.36"
]
def ip_parse_xici(page):
"""
:param page: 采集的頁數
:return:
"""
ip_list = []
for pg in range(1, int(page)):
url = 'http://www.xicidaili.com/nn/' + str(pg)
user_agent = random.choice(ua_list)
my_headers = {
'Accept': 'text/html, application/xhtml+xml, application/xml;',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Referer': 'http: // www.xicidaili.com/nn',
'User-Agent': user_agent
}
try:
r = requests.get(url, headers=my_headers)
soup = BeautifulSoup(r.text, 'html.parser')
except requests.exceptions.ConnectionError:
print('ConnectionError')
else:
data = soup.find_all('td')
# 定義IP和端口Pattern規則
ip_compile = re.compile(r'<td>(\d+\.\d+\.\d+\.\d+)</td>') # 匹配IP
port_compile = re.compile(r'<td>(\d+)</td>') # 匹配端口
ips = re.findall(ip_compile, str(data)) # 獲取所有IP
ports = re.findall(port_compile, str(data)) # 獲取所有端口
check_api = "http://ip.taobao.com/service/getIpInfo2.php?ip="
for i in range(len(ips)):
if i < len(ips):
ip = ips[i]
api = check_api + ip
api_headers = {
'User-Agent': user_agent
}
try:
response = requests.get(url=api, headers=api_headers, timeout=2)
print("ip:%s 可用" % ip)
except Exception as e:
print("此ip %s 已失效:%s" % (ip, e))
del ips[i]
del ports[i]
ips_usable = ips
ip_list += [':'.join(n) for n in zip(ips_usable, ports)] # 列表生成式
print('第{}頁ip采集完成'.format(pg))
print(ip_list)
if __name__ == '__main__':
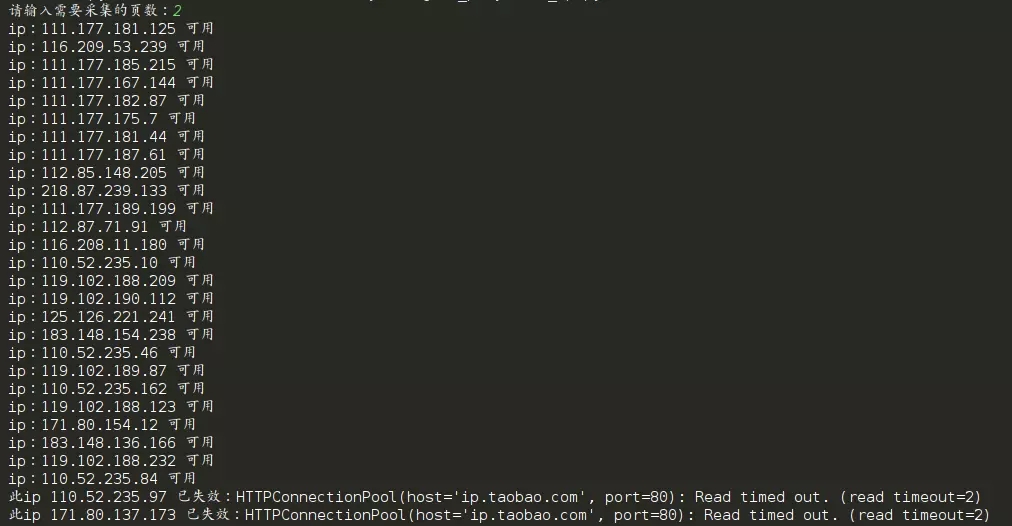
xici_pg = input("請輸入需要采集的頁數:")
ip_parse_xici(page=xici_pg)
運行代碼:
4.為你的爬蟲加入代理ip
建議大家可以把采集的ip存入數據庫,這樣每次爬蟲的時候直接調用即可,順便提一下代碼中怎么加入代理ip。
import requests
url = 'www.baidu.com'
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36",
}
proxies = {
"http": "http://111.177.181.44:9999",
# "https": "https://111.177.181.44:9999",
}
res = requests.get(url=url, headers=headers, proxies=proxies)
好了,媽媽再也不擔心我爬蟲被封了
以上所述是小編給大家介紹的爬蟲被封的問題詳解整合,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對億速云網站的支持!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





