溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關groupby( )函數怎么在Pandas中使用,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
groupby官方解釋
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Group series using mapper (dict or key function, apply given function to group, return result as series) or by a series of columns.
講真的,非常不能理解pandas官方文檔的這種表達形式,讓人真的有點摸不著頭腦,example給得又少,參數也不給得很清楚,不過沒有辦法,還是只能選擇原諒他。
groupby我用過的用法
基本用法我這里就不呈現了,我覺得用過一次的人基本不會忘記,這里我主要寫一下我用過的關系groupby函數的疑惑:
apply & agg
這個問題著實困擾了我很久,經過研究,找了一些可能幫助理解的東西。先舉一個例子:
import pandas as pd
df = pd.DataFrame({'Q':['LI','ZHANG','ZHANG','LI','WANG'], 'A' : [1,1,1,2,2], 'B' : [1,-1,0,1,2], 'C' : [3,4,5,6,7]})| A | B | C | Q | |
|---|---|---|---|---|
| 0 | 1 | 1 | 3 | LI |
| 1 | 1 | -1 | 4 | ZHANG |
| 2 | 1 | 0 | 5 | ZHANG |
| 3 | 2 | 1 | 6 | LI |
| 4 | 2 | 2 | 7 | WANG |
df.groupby('Q').apply(lambda x:print(x))A B C Q
0 1 1 3 LI
3 2 1 6 LI
A B C Q
0 1 1 3 LI
3 2 1 6 LI
A B C Q
4 2 2 7 WANG
A B C Q
1 1 -1 4 ZHANG
2 1 0 5 ZHANG
df.groupby('Q').agg(lambda x:print(x))0 1
3 2
Name: A, dtype: int64
4 2
Name: A, dtype: int64
1 1
2 1
Name: A, dtype: int64
0 1
3 1
Name: B, dtype: int64
4 2
Name: B, dtype: int64
1 -1
2 0
Name: B, dtype: int64
0 3
3 6
Name: C, dtype: int64
4 7
Name: C, dtype: int64
1 4
2 5
Name: C, dtype: int64
| A | B | C | |
|---|---|---|---|
| Q | |||
| LI | None | None | None |
| WANG | None | None | None |
| ZHANG | None | None | None |
從這個例子可以看出,使用apply()處理的對象是一個個的類如DataFrame的數據表,然而agg()則每次只傳入一列。
不過我覺得這一點區別在實際應用中分別并不大,因為Ipython的Out輸出對于這兩個函數幾乎沒有差別,不管是處理一列還是一表。
我覺得agg()有一點讓我很開心就是他可以同時傳入多個函數,簡直不要太方便哈哈:
df.groupby('Q').agg(['mean','std','count','max'])| A | B | C | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | std | count | max | mean | std | count | max | mean | std | count | max | |
| Q | ||||||||||||
| LI | 1.5 | 0.707107 | 2 | 2 | 1.0 | 0.000000 | 2 | 1 | 4.5 | 2.121320 | 2 | 6 |
| WANG | 2.0 | NaN | 1 | 2 | 2.0 | NaN | 1 | 2 | 7.0 | NaN | 1 | 7 |
| ZHANG | 1.0 | 0.000000 | 2 | 1 | -0.5 | 0.707107 | 2 | 0 | 4.5 | 0.707107 | 2 | 5 |
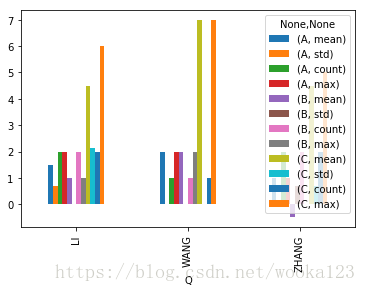
Plotting
這個也是我剛剛學會的,groupby的plot簡直不要太方便了:(不過這個例子選的不是很好)
%matplotlib inline
df.groupby('Q').agg(['mean','std','count','max']).plot(kind='bar')<matplotlib.axes._subplots.AxesSubplot at 0x1133bd710>
MultiIndex
這個是困擾我最多的一個問題,因為如果我groupby的時候選擇了兩個level,之后的data總是呈現透視表的形式,如:
Muldf = df.groupby(['Q','A']).agg('mean')
print(Muldf)B C
Q A
LI 1 1.0 3.0
2 1.0 6.0
WANG 2 2.0 7.0
ZHANG 1 -0.5 4.5
我開始甚至以為這應該不是dataframe,是一個我可能沒注意過的一個東西,可是后來我發現,這不過是MultiIndex形式的一種dataframe罷了。
Muldf.B
Q A
LI 1 1.0
2 1.0
WANG 2 2.0
ZHANG 1 -0.5
Name: B, dtype: float64
如果要選擇某一個index,用`xs()`函數:
Muldf.xs('LI')| B | C | |
|---|---|---|
| A | ||
| 1 | 1.0 | 3.0 |
| 2 | 1.0 | 6.0 |
PS:有個問題困擾好久了,怎么把multiindex對象變回原來的形式呢。如:
Multiindex格式如下:(a, b, c, ...),
| index | column |
| (a1,b1,c1) | d1 |
| (a2,b2,c2) | d2 |
直接調用函數reset_index(),Multiindex中(a, b, c, ...)就變成columns了,index重置為(0,1,2,...), 如下:
| index | column | |||
| 0 | a1 | b1 | c1 | d1 |
| 1 | a2 | b2 | c2 | d2 |
上述就是小編為大家分享的groupby( )函數怎么在Pandas中使用了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





