溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
多路復用IO(IO multiplexing)
這種IO方式為事件驅動IO(event driven IO)。
我們都知道,select/epoll的好處就在于單個進程process就可以同時處理多個網絡連接的IO。它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有數據到達了,就通知用戶進程。它的流程如圖:
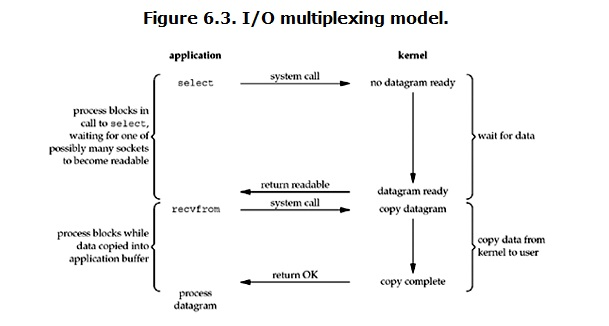
select是多路復用的一種
當用戶進程調用了select,那么整個進程會被block,而同時,kernel會“監視”所有select負責的socket,
當任何一個socket中的數據準備好了,select就會返回。這個時候用戶進程再調用read操作,將數據從kernel拷貝到用戶進程。
這個圖和blocking IO的圖其實并沒有太大的不同,事實上還更差一些。因為這里需要使用兩個系統調用\(select和recvfrom\),
而blocking IO只調用了一個系統調用\(recvfrom\)。但是,用select的優勢在于它可以同時處理多個connection。
多路復用IO比較阻塞IO模型:
1.阻塞IO經歷兩個階段 wait data,copy data
2.多路復用3個階段 wait data,ready copy data, copy data
單連接套接字通信 阻塞IO效率高
多路復用IO select可以代理多個套接字連接,多個套接字通信,多路復用IO效率高
強調:
1. 如果處理的連接數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延遲還更大。select/epoll的優勢并不是對于單個連接能處理得更快,而是在于能處理更多的連接。
2. 在多路復用模型中,對于每一個socket,一般都設置成為non-blocking,但是,如上圖所示,整個用戶的process其實是一直被block的。只不過process是被select這個函數block,而不是被socket IO給block。
結論: select的優勢在于可以處理多個連接,性能高,同時可以檢測多個套接字IO行為,不適用于單個連接
select網絡IO模型示例
select 檢測多個套接字IO行為 accept,recv
IO行為兩種:
1.別人給我傳數據
2.給別人發送數據
timeout是超時時間
每隔0.5秒去問操作系統準備好數據沒有
def select(rlist, wlist, xlist, timeout=None): pass # [] 傳的空列表是出異常的列表 # 返回值3個列表 收列表,發列表,異常列表 rl,wl,xl = select.select(rlist, wlist, [], 0.5)
客戶端:
from socket import *
client = socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8000))
while True:
msg = input(">>>:").strip()
if not msg:continue
client.send(msg.encode("utf-8"))
data = client.recv(1024)
print(data.decode("utf-8"))
client.close()
服務端代碼:
from socket import *
import select
server = socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8000))
server.listen(5)
# 設置socket接口為 非阻塞IO接口
# 默認是True 為阻塞
server.setblocking(False)
# 專門存著收消息套接字
rlist = [server,]
# 存放發送消息套接字
wlist = []
# 存放發送的數據
wdata = {}
while True:
# 返回值3個列表 收列表,發列表,異常列表
rl,wl,xl = select.select(rlist, wlist, [], 0.5)
print("rl",rl)
print("wl",wl)
for sock in rl:
if sock == server:
conn,addr = sock.accept()
rlist.append(conn)
else:
try:
data = sock.recv(1024)
if not data:
sock.close()
rlist.remove(sock)
continue
# 收的套接字加到列表
wlist.append(sock)
# 把數據加到字典 做一個 套接字對應數據
wdata[sock] = data.upper()
except Exception:
sock.close()
rlist.remove(sock)
# 發送數據
for sock in wl:
sock.send(wdata[sock])
wlist.remove(sock)
wdata.pop(sock)
server.close()
基于select模塊 檢測套接字IO行為,實現并發效果
select監聽fd變化的過程分析:
用戶進程創建socket對象,拷貝監聽的fd到內核空間,每一個fd會對應一張系統文件表,內核空間的fd響應到數據后,
就會發送信號給用戶進程數據已到;
用戶進程再發送系統調用,比如(accept)將內核空間的數據copy到用戶空間,同時作為接受數據端內核空間的數據清除,
這樣重新監聽時fd再有新的數據又可以響應到了(發送端因為基于TCP協議所以需要收到應答后才會清除)。
該模型的優點:
可以同時檢測多個套接字,效率比阻塞IO,非阻塞IO高了
相比其他模型,使用select() 的事件驅動模型只用單線程(進程)執行,占用資源少,不消耗太多 CPU,同時能夠為多客戶端提供服務。
如果試圖建立一個簡單的事件驅動的服務器程序,這個模型有一定的參考價值。
該模型的缺點:
代理的套接字 列表里的多個套接字,需要循環列表 一個個檢測,
在代理套接字比較少的情況下,循環比較快。但select代理的套接字非常多的情況下,select隨著列表增大,效率就越來越慢
首先select()接口并不是實現“事件驅動”的最好選擇。因為當需要探測的句柄值較大時,select()接口本身需要消耗大量時間去輪詢各個句柄。
很多操作系統提供了更為高效的接口,如linux提供了epoll,BSD提供了kqueue,Solaris提供了/dev/poll,…。
如果需要實現更高效的服務器程序,類似epoll這樣的接口更被推薦。遺憾的是不同的操作系統特供的epoll接口有很大差異,
所以使用類似于epoll的接口實現具有較好跨平臺能力的服務器會比較困難。
其次,該模型將事件探測和事件響應夾雜在一起,一旦事件響應的執行體龐大,則對整個模型是災難性的。
epoll是異步方式實現,提交套接字時候,每個套接字身上都綁定一個回調函數,哪個套接字準備好了,就觸發回調函數,把自己索引放在單獨列表里,對于select來說,只需要去準備好的列表里 根據索引拿到套接字,這樣不需要在列表里每個遍歷。
epoll不支持windows系統
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





