溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
1、在Tomcat 的安裝路徑下,找到bin/catalina.sh 加上下面的配置,具體參數,自己配置:
[root@centos7 tomcat]# vim bin/catalina.sh

2、重啟tomcat
[root@centos7 ~]# systemctl restart tomcat
3、查看GC日志
[root@centos7 ~]# cat /usr/local/tomcat/logs/tomcat_gc.log
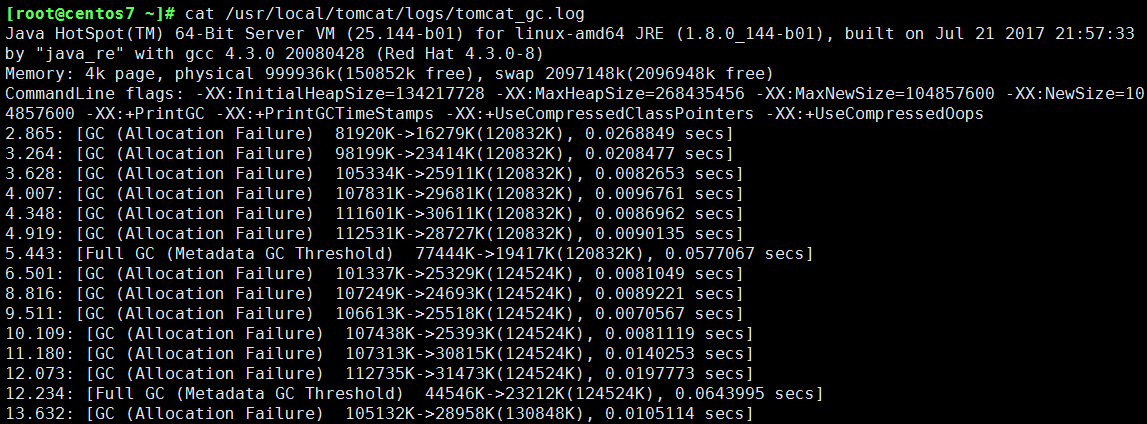
若只是使用,搞懂配置,只需看第二、三、四即可;若想更深入的了解GC,請詳細看完~
GC 日志分析,需使用windows 的GC日志分析工具gchisto;
gchisto 工具的源下載地址:http://xz.jb51.net:81/201806/yuanma/GChisto_jb51.rar
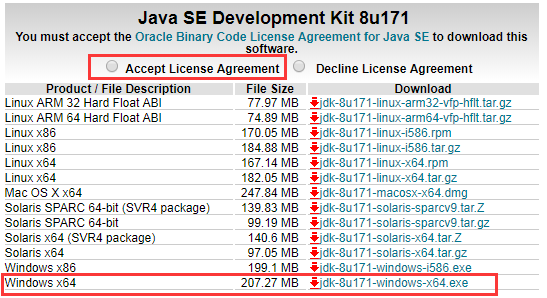
(1)去官網下載自己想要的JDK版本
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下載,必須點擊同意協議
(2)安裝JDK1.8版本
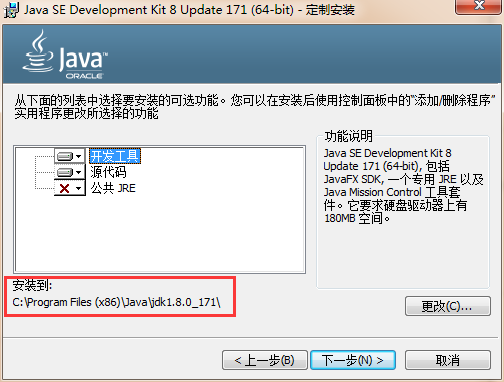
設置自己的安裝路徑,取消公告JRE
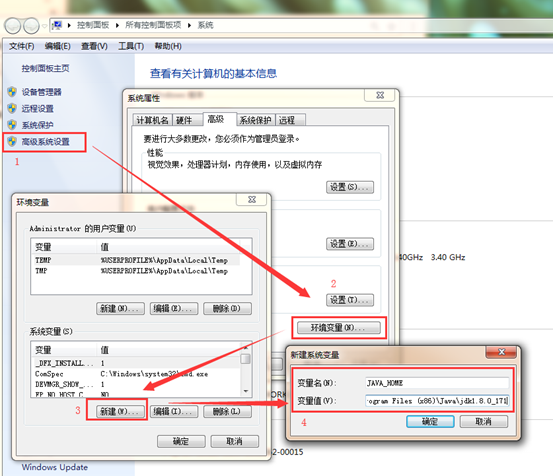
(3)設置3個環境變量
① 找到自己安裝jdk的bin路徑,我的安裝路徑是 C:\Program Files (x86)\Java\jdk1.8.0_171

② 在高級系統設置--->環境變量--->新建
新建2個環境變量:
JAVA_HOME
CLASSPATH
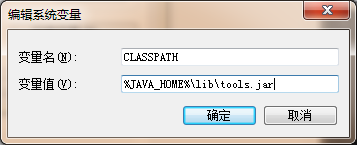
修改一個變量:Path
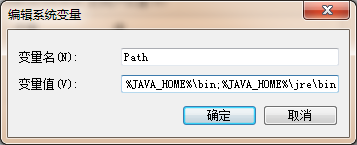
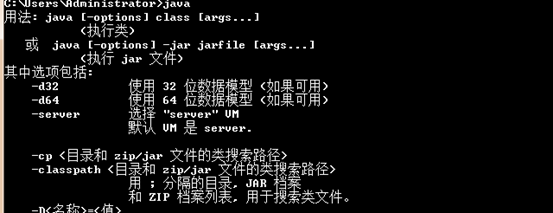
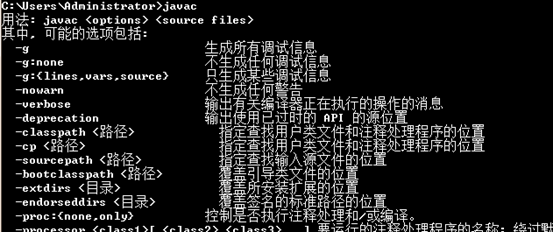
(4)安裝完畢,測試
java、javac、java -version 三個命令會有以下效果

(1)運行gchisto
解包后,打開cmd命令行,執行下邊的命令,注意:自己解包后gchisto的路徑
>java -jar D:\gchisto-master\release\GCHisto-java8.jar
(2)打開后效果
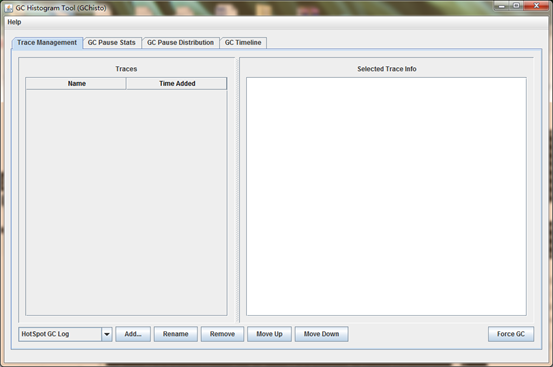
(3)分析Tomcat 的gc 日志
① 將linux 下的tomcat 日志sz 到windows 上;
② 導入gchisto中;
③ 查看效果
① -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-Xmx3550m:設置JVM最大可用內存為3550M。
-Xms3550m:設置JVM初始內存為3550m。此值可以設置與-Xmx相同,以避免每次垃圾回收完成后JVM重新分配內存。
-Xmn2g:設置年輕代大小為2G。整個堆大小=年輕代大小 + 年老代大小 + 持久代大小。持久代一般固定大小為64m,所以增大年輕代后,將會減小年老代大小。此值對系統性能影響較大,Sun官方推薦配置為整個堆的3/8。
-Xss128k: 設置每個線程的堆棧大小。JDK5.0以后每個線程堆棧大小為1M,以前每個線程堆棧大小為256K。更具應用的線程所需內存大小進行調整。在相同物理內存下,減小這個值能生成更多的線程。但是操作系統對一個進程內的線程數還是有限制的,不能無限生成,經驗值在3000~5000左右。
② -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:設置年輕代(包括Eden和兩個Survivor區)與年老代的比值(除去持久代)。設置為4,則年輕代與年老代所占比值為1:4,年輕代占整個堆棧的1/5
-XX:SurvivorRatio=4:設置年輕代中Eden區與Survivor區的大小比值。設置為4,則兩個Survivor區與一個Eden區的比值為2:4,一個Survivor區占整個年輕代的1/6
-XX:PermSize:設置永久代(perm gen)初始值。默認值為物理內存的1/64。
-XX:MaxPermSize:設置持久代最大值。物理內存的1/4。
-XX:MaxTenuringThreshold=0:設置垃圾最大年齡。如果設置為0的話,則年輕代對象不經過Survivor區,直接進入年老代。對于年老代比較多的應用,可以提高效率。如果將此值設置為一個較大值,則年輕代對象會在Survivor區進行多次復制,這樣可以增加對象再年輕代的存活時間,增加在年輕代即被回收的概論。
(1)吞吐量優先的并行收集器
① -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelGC:選擇垃圾收集器為并行收集器。此配置僅對年輕代有效。即上述配置下,年輕代使用并發收集,而年老代仍舊使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的線程數,即:同時多少個線程一起進行垃圾回收。此值最好配置與處理器數目相等。
② -XX:+UseParallelOldGC
-XX:+UseParallelOldGC:配置年老代垃圾收集方式為并行收集。JDK6.0支持對年老代并行收集。
③ -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100:設置每次年輕代垃圾回收的最長時間,如果無法滿足此時間,JVM會自動調整年輕代大小,以滿足此值。
④ -XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy:設置此選項后,并行收集器會自動選擇年輕代區大小和相應的Survivor區比例,以達到目標系統規定的最低相應時間或者收集頻率等,此值建議使用并行收集器時,一直打開。
(2)響應時間優先的并發收集器
① -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+UseConcMarkSweepGC:設置年老代為并發收集。測試中配置這個以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此時年輕代大小最好用-Xmn設置。
-XX:+UseParNewGC:設置年輕代為并行收集。可與CMS收集同時使用。JDK5.0以上,JVM會根據系統配置自行設置,所以無需再設置此值。
② -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction:由于并發收集器不對內存空間進行壓縮、整理,所以運行一段時間以后會產生"碎片",使得運行效率降低。此值設置運行多少次GC以后對內存空間進行壓縮、整理。
-XX:+UseCMSCompactAtFullCollection:打開對年老代的壓縮。可能會影響性能,但是可以消除碎片
JVM提供了大量命令行參數,打印信息,供調試使用。主要有以下一些:
① -XX:+PrintGC
輸出形式:
[GC 118250K->113543K(130112K), 0.0094143 secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs]
② -XX:+PrintGCDetails
輸出形式:
[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs]
[GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
③ -XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可與上面兩個混合使用
輸出形式:
11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
④ -XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中斷的執行時間。可與上面混合使用
輸出形式:
Application time: 0.5291524 seconds
⑤ -XX:+PrintGCApplicationStoppedTime:打印垃圾回收期間程序暫停的時間。可與上面混合使用
輸出形式:
Total time for which application threads were stopped: 0.0468229 seconds
⑥ -XX:PrintHeapAtGC:打印GC前后的詳細堆棧信息
輸出形式:
34.702: [GC {Heap before gc invocations=7:
def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000)
to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
}
, 0.0757599 secs]
⑦ -Xloggc:filename:與上面幾個配合使用,把相關日志信息記錄到文件以便分析。
① -Xms:初始堆大小
② -Xmx:最大堆大小
③ -XX:NewSize=n:設置年輕代大小
④ -XX:NewRatio=n:設置年輕代和年老代的比值。如:為3,表示年輕代與年老代比值為1:3,年輕代占整個年輕代年老代和的1/4
⑤ -XX:SurvivorRatio=n:年輕代中Eden區與兩個Survivor區的比值。注意Survivor區有兩個。如:3,表示Eden:Survivor=3:2,一個Survivor區占整個年輕代的1/5
⑥ -XX:MaxPermSize=n:設置持久代大小
① -XX:+UseSerialGC:設置串行收集器
② -XX:+UseParallelGC:設置并行收集器
③ -XX:+UseParalledlOldGC:設置并行年老代收集器
④ -XX:+UseConcMarkSweepGC:設置并發收集器
① -XX:+PrintGC
② -XX:+PrintGCDetails
③ -XX:+PrintGCTimeStamps
④ -Xloggc:filename
① -XX:ParallelGCThreads=n:設置并行收集器收集時使用的CPU數。并行收集線程數。
② -XX:MaxGCPauseMillis=n:設置并行收集最大暫停時間
③ -XX:GCTimeRatio=n:設置垃圾回收時間占程序運行時間的百分比。公式為1/(1+n)
① -XX:+CMSIncrementalMode:設置為增量模式。適用于單CPU情況。
② -XX:ParallelGCThreads=n:設置并發收集器年輕代收集方式為并行收集時,使用的CPU數。并行收集線程數。
① 響應時間優先的應用:盡可能設大,直到接近系統的最低響應時間限制(根據實際情況選擇)。在此種情況下,年輕代收集發生的頻率也是最小的。同時,減少到達年老代的對象。
② 吞吐量優先的應用:盡可能的設置大,可能到達Gbit的程度。因為對響應時間沒有要求,垃圾收集可以并行進行,一般適合8CPU以上的應用。
① 響應時間優先的應用:年老代使用并發收集器,所以其大小需要小心設置,一般要考慮并發會話率和會話持續時間等一些參數。如果堆設置小了,可以會造成內存碎片、高回收頻率以及應用暫停而使用傳統的標記清除方式;如果堆大了,則需要較長的收集時間。最優化的方案,一般需要參考以下數據獲得:
并發垃圾收集信息
持久代并發收集次數
傳統GC信息
花在年輕代和年老代回收上的時間比例
減少年輕代和年老代花費的時間,一般會提高應用的效率
② 吞吐量優先的應用:一般吞吐量優先的應用都有一個很大的年輕代和一個較小的年老代。原因是,這樣可以盡可能回收掉大部分短期對象,減少中期的對象,而年老代盡存放長期存活對象。
因為年老代的并發收集器使用標記、清除算法,所以不會對堆進行壓縮。當收集器回收時,他會把相鄰的空間進行合并,這樣可以分配給較大的對象。但是,當堆空間 較小時,運行一段時間以后,就會出現"碎片",如果并發收集器找不到足夠的空間,那么并發收集器將會停止,然后使用傳統的標記、清除方式進行回收。如果出 現"碎片",可能需要進行如下配置:
① -XX:+UseCMSCompactAtFullCollection:使用并發收集器時,開啟對年老代的壓縮。
② -XX:CMSFullGCsBeforeCompaction=0:上面配置開啟的情況下,這里設置多少次Full GC后,對年老代進行壓縮
(1)Young(年輕代)
年輕代分三個區。一個Eden區,兩個Survivor區。大部分對象在Eden區中生成。當Eden區滿時,還存活的對象將被復制到Survivor區 (兩個中的一個),當這個Survivor區滿時,此區的存活對象將被復制到另外一個Survivor區,當這個Survivor去也滿了的時候,從第一 個Survivor區復制過來的并且此時還存活的對象,將被復制"年老區(Tenured)"。需要注意,Survivor的兩個區是對稱的,沒先后關系,所以同一個區中可能同時存在從Eden復制過來 對象,和從前一個Survivor復制過來的對象,而復制到年老區的只有從第一個Survivor去過來的對象。而且,Survivor區總有一個是空 的。
(2)Tenured(年老代)
年老代存放從年輕代存活的對象。一般來說年老代存放的都是生命期較長的對象。
(3)Perm(持久代)
用于存放靜態文件,如今Java類、方法等。持久代對垃圾回收沒有顯著影響,但是有些應用可能動態生成或者調用一些class,例如Hibernate等, 在這種時候需要設置一個比較大的持久代空間來存放這些運行過程中新增的類。持久代大小通過-XX:MaxPermSize=進行設置。
GC有兩種類型:Scavenge GC和Full GC。
(1)Scavenge GC
一般情況下,當新對象生成,并且在Eden申請空間失敗時,就好觸發Scavenge GC,堆Eden區域進行GC,清除非存活對象,并且把尚且存活的對象移動到Survivor區。然后整理Survivor的兩個區。
(2)Full GC
對整個堆進行整理,包括Young、Tenured和Perm。Full GC比Scavenge GC要慢,因此應該盡可能減少Full GC。有如下原因可能導致Full GC:
目前的收集器主要有三種:串行收集器、并行收集器、并發收集器。
(1)串行收集器
使用單線程處理所有垃圾回收工作,因為無需多線程交互,所以效率比較高。但是,也無法使用多處理器的優勢,所以此收集器適合單處理器機器。當然,此收集器也可以用在小數據量(100M左右)情況下的多處理器機器上。可以使用-XX:+UseSerialGC打開。
(2)并行收集器
對年輕代進行并行垃圾回收,因此可以減少垃圾回收時間。一般在多線程多處理器機器上使用。使用-XX:+UseParallelGC.打開。并行收集器在J2SE5.0第六6更新上引入,在Java SE6.0中進行了增強--可以堆年老代進行并行收集。如果年老代不使用并發收集的話,是使用單線程進行垃圾回收,因此會制約擴展能力。使用-XX:+UseParallelOldGC打開。
使用-XX:ParallelGCThreads=設置并行垃圾回收的線程數。此值可以設置與機器處理器數量相等。
此收集器可以進行如下配置:
(3)并發收集器
可以保證大部分工作都并發進行(應用不停止),垃圾回收只暫停很少的時間,此收集器適合對響應時間要求比較高的中、大規模應用。使用-XX:+UseConcMarkSweepGC打開。
(4)小結
① 串行處理器:
--適用情況:數據量比較小(100M左右);單處理器下并且對響應時間無要求的應用。
--缺點:只能用于小型應用
② 并行處理器:
--適用情況:"對吞吐量有高要求",多CPU、對應用響應時間無要求的中、大型應用。舉例:后臺處理、科學計算。
--缺點:應用響應時間可能較長
③ 并發處理器:
--適用情況:"對響應時間有高要求",多CPU、對應用響應時間有較高要求的中、大型應用。舉例:Web服務器/應用服務器、電信交換、集成開發環境。
(1)引用計數(Reference Counting)
比較古老的回收算法。原理是此對象有一個引用,即增加一個計數,刪除一個引用則減少一個計數。垃圾回收時,只用收集計數為0的對象。此算法最致命的是無法處理循環引用的問題。
(2)標記-清除(Mark-Sweep)
此算法執行分兩階段。第一階段從引用根節點開始標記所有被引用的對象,第二階段遍歷整個堆,把未標記的對象清除。此算法需要暫停整個應用,同時,會產生內存碎片。
(3)復制(Copying)
此算法把內存空間劃為兩個相等的區域,每次只使用其中一個區域。垃圾回收時,遍歷當前使用區域,把正在使用中的對象復制到另外一個區域中。次算法每次只處理 正在使用中的對象,因此復制成本比較小,同時復制過去以后還能進行相應的內存整理,不過出現"碎片"問題。當然,此算法的缺點也是很明顯的,就是需要兩倍 內存空間。
(4)標記-整理(Mark-Compact)
此算法結合了"標記-清除"和"復 制"兩個算法的優點。也是分兩階段,第一階段從根節點開始標記所有被引用對象,第二階段遍歷整個堆,把清除未標記對象并且把存活對象"壓縮"到堆的其中一 塊,按順序排放。此算法避免了"標記-清除"的碎片問題,同時也避免了"復制"算法的空間問題。
(5)增量收集(Incremental Collecting)
實施垃圾回收算法,即:在應用進行的同時進行垃圾回收。不知道什么原因JDK5.0中的收集器沒有使用這種算法的。
(6)分代(Generational Collecting)
基于對對象生命周期分析后得出的垃圾回收算法。把對象分為年青代、年老代、持久代,對不同生命周期的對象使用不同的算法(上述方式中的一個)進行回收。現在的垃圾回收器(從J2SE1.2開始)都是使用此算法的。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





