溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Python3如何實現zip分卷壓縮,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
1、簡單易用,與C/C++、Java、C# 等傳統語言相比,Python對代碼格式的要求沒有那么嚴格;2、Python屬于開源的,所有人都可以看到源代碼,并且可以被移植在許多平臺上使用;3、Python面向對象,能夠支持面向過程編程,也支持面向對象編程;4、Python是一種解釋性語言,Python寫的程序不需要編譯成二進制代碼,可以直接從源代碼運行程序;5、Python功能強大,擁有的模塊眾多,基本能夠實現所有的常見功能。
使用zipfile庫
利用 Python 壓縮 ZIP 文件,我們第一反應是使用 zipfile 庫,然而,它的官方文檔中卻明確標注“此模塊目前不能處理分卷 ZIP 文件”
折騰經過
翻遍了Google、CSDN、Stackoverflow等平臺均未找到解決方案,最靠譜的是調用外部解壓程序實現分卷壓縮的功能。但是,如何不依靠外部程序實現這個功能呢??
于是乎,只能自己慢慢造輪子。看著 ZIP 格式開發商留下的文檔 ZIP File Format Specification,頭疼啊(;´д`)。于是我拿著 WinHex 開始16進制一個一個文件對比 WinRar 創建的分卷壓縮和單個 zip 文件的差異。
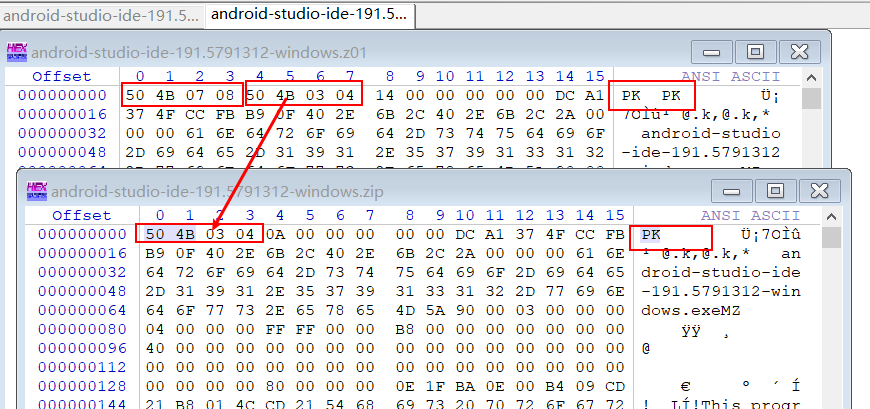
如果想把單個大文件 test.zip -> 分卷文件 test.z01、test.z02、test.zip
首先,在創建的第一個分卷文件 test.z01的前面加上 \x50\x4b\x07\x08 這個是分卷壓縮的文件頭(header),占4個字節。其實單個壓縮文件本身 header 就有這個了,而分卷壓縮的需要兩個emmm。之后便是從單個大壓縮文件文件test.zip中讀取 "一個分卷大小 -4 個字節"的數據,寫入test.z01中,如何接著讀取一個分卷大小的數據,寫入test.z02,以此類推,最后一個分卷文件名也是test.zip。
Python3的代碼實現
import os
import zipfile
def zip_by_volume(file_path, block_size):
"""zip文件分卷壓縮"""
file_size = os.path.getsize(file_path) # 文件字節數
path, file_name = os.path.split(file_path) # 除去文件名以外的path,文件名
suffix = file_name.split('.')[-1] # 文件后綴名
# 添加到臨時壓縮文件
zip_file = file_path + '.zip'
with zipfile.ZipFile(zip_file, 'w') as zf:
zf.write(file_path, arcname=file_name)
# 小于分卷尺寸則直接返回壓縮文件路徑
if file_size <= block_size:
return zip_file
else:
fp = open(zip_file, 'rb')
count = file_size // block_size + 1
# 創建分卷壓縮文件的保存路徑
save_dir = path + os.sep + file_name + '_split'
if os.path.exists(save_dir):
from shutil import rmtree
rmtree(save_dir)
os.mkdir(save_dir)
# 拆分壓縮包為分卷文件
for i in range(1, count + 1):
_suffix = 'z{:0>2}'.format(i) if i != count else 'zip'
name = save_dir + os.sep + file_name.replace(str(suffix), _suffix)
f = open(name, 'wb+')
if i == 1:
f.write(b'\x50\x4b\x07\x08') # 添加分卷壓縮header(4字節)
f.write(fp.read(block_size - 4))
else:
f.write(fp.read(block_size))
fp.close()
os.remove(zip_file) # 刪除臨時的 zip 文件
return save_dir
if __name__ == '__main__':
file = r"D:\Downloads\1.mp4" # 原始文件
volume_size = 1024 * 1024 * 100 # 分卷大小 100MB
path = zip_by_volume(file, volume_size)
print(path) # 輸出分卷壓縮文件的路徑缺點
該方法創建分卷壓縮的時候,需要先在磁盤創建一個臨時壓縮包,然后將其拆分,實際上會對磁盤寫入兩次,這就浪費了時間。
當然,我嘗試使用 ByteIO 進行字節流的壓縮,但是這種方式需要先把文件讀入內存,對于超級大的文件,這是不現實的,分分鐘內存爆炸。
然后,我嘗試使用 io.pipe 的管道來處理,而 zipfile 壓縮需要提供一個 file 或 file-like 對象,這個對象必須實現 seek() 和 tell() 方法來回去寫入文件頭信息,然而管道流沒辦法seek回去修改數據。這里,參考了Python zipfile + os.pipe()探索記,屏蔽了 seek() 和 tell() 函數。但是,后面我分卷時需要指定讀取的字節數,這就需要這兩個函數。。。我大概知道為什么 zipfile 庫不支持創建分卷文件了
以上是“Python3如何實現zip分卷壓縮”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





