溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關怎么在Python項目中使用lxml庫解析html文件,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
lxml是Python的一個html/xml解析并建立dom的庫,lxml的特點是功能強大,性能也不錯,xml包含了ElementTree ,html5lib ,beautfulsoup 等庫。
使用lxml前注意事項:先確保html經過了utf-8解碼,即code =html.decode('utf-8', 'ignore'),否則會出現解析出錯情況。因為中文被編碼成utf-8之后變成 '/u2541' 之類的形式,lxml一遇到 "/"就會認為其標簽結束。
具體用法:元素節點操作
1、 解析HTMl建立DOM
from lxml import etree dom = etree.HTML(html)
2、 查看dom中子元素的個數 len(dom)
3、 查看某節點的內容:etree.tostring(dom[0])
4、 獲取節點的標簽名稱:dom[0].tag
5、 獲取某節點的父節點:dom[0].getparent()
6、 獲取某節點的屬性節點的內容:dom[0].get("屬性名稱")
對xpath路徑的支持:
XPath即為XML路徑語言,是用一種類似目錄樹的方法來描述在XML文檔中的路徑。比如用"/"來作為上下層級間的分隔。第一個"/"表示文檔的根節點(注意,不是指文檔最外層的tag節點,而是指文檔本身)。比如對于一個HTML文件來說,最外層的節點應該是"/html"。
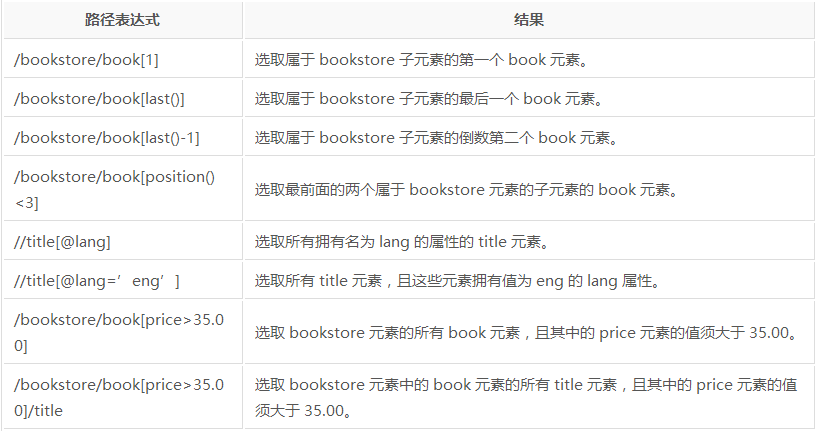
xpath選取元素的方式:
1、 絕對路徑,如page.xpath("/html/body/p"),它會找到body這個節點下所有的p標簽
2、 相對路徑,page.xpath("//p"),它會找到整個html代碼里的所有p標簽。

xpath篩選方式:
1、 選取元素時一個列表,可通過索引查找[n]
2、 通過屬性值篩選元素p =page.xpath("//p[@style='font-size:200%']")
3、 如果沒有屬性可以通過text()(獲取元素中文本)、position()(獲取元素位置)、last()等進行篩選
獲取屬性值
dom.xpath(.//a/@href)
獲取文本
dom.xpath(".//a/text()")示例代碼:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from scrapy.spiders import Spider
from lxml import etree
from jredu.items import JreduItem
class JreduSpider(Spider):
name = 'tt' #爬蟲的名字,必須的,唯一的
allowed_domains = ['sohu.com']
start_urls = [
'http://www.sohu.com'
]
def parse(self, response):
content = response.body.decode('utf-8')
dom = etree.HTML(content)
for ul in dom.xpath("//div[@class='focus-news-box']/div[@class='list16']/ul"):
lis = ul.xpath("./li")
for li in lis:
item = JreduItem() #定義對象
if ul.index(li) == 0:
strong = li.xpath("./a/strong/text()")
li.xpath("./a/@href")
item['title']= strong[0]
item['href'] = li.xpath("./a/@href")[0]
else:
la = li.xpath("./a[last()]/text()")
item['title'] = la[0]
item['href'] = li.xpath("./a[last()]/href")[0]
yield item上述就是小編為大家分享的怎么在Python項目中使用lxml庫解析html文件了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





