溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
某天氣網站(www.數字.com)存有2011年至今的天氣數據,有天看到一本爬蟲教材提到了爬取這些數據的方法,學習之,并加以改進。
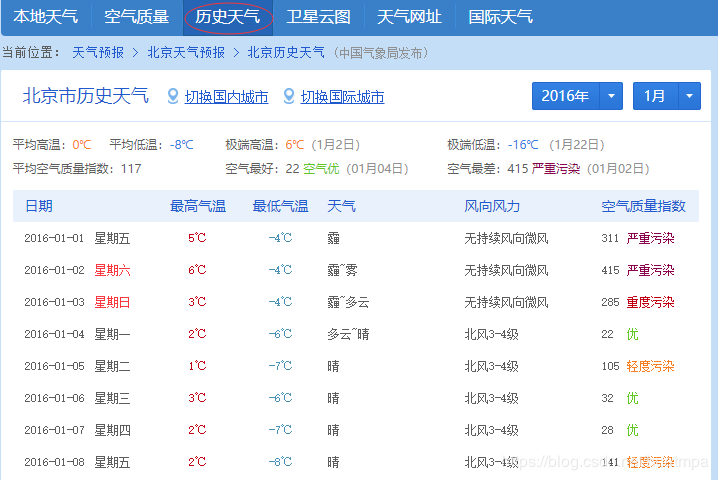
準備爬的歷史天氣
爬之前先分析url。左上有年份、月份的下拉選擇框,按F12,進去看看能否找到真正的url:
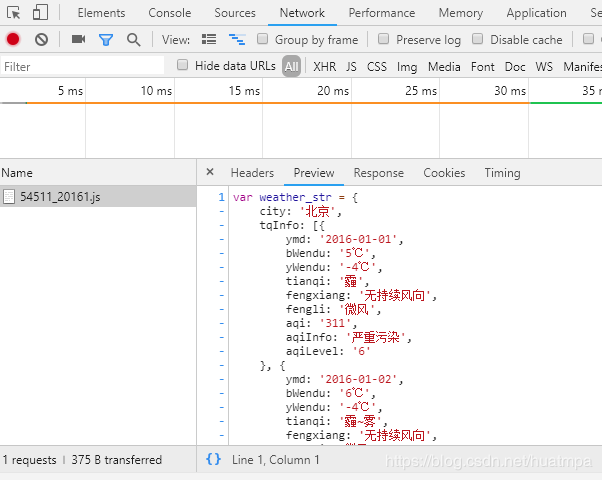
很容易就找到了,左邊是儲存月度數據的js文件,右邊是文件源代碼,貌似json格式。
雙擊左邊js文件,地址欄內出現了url:http://tianqi.數字.com/t/wea_history/js/54511_20161.js
url中的“54511”是城市代碼,“20161”是年份和月份代碼。下一步就是找到城市代碼列表,按城市+年份+月份構造url列表,就能開始遍歷爬取了。
城市代碼也很誠實,很快就找到了:
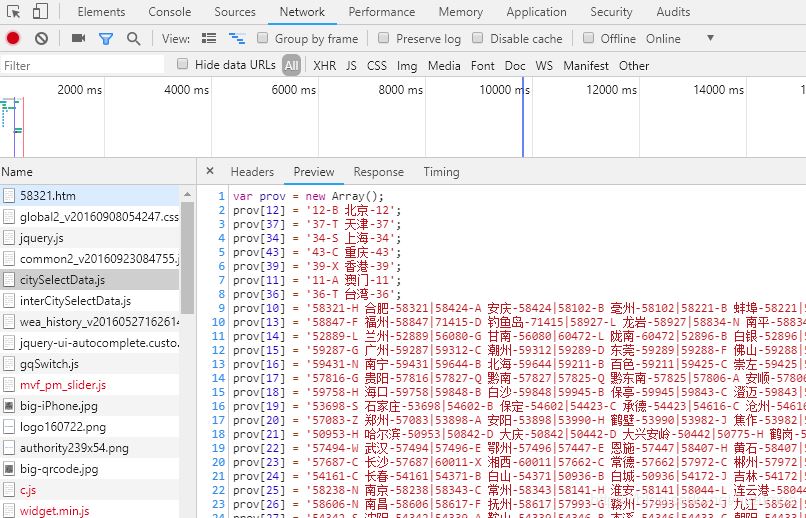
下一步得把城市名稱和代碼提取出來,構造一個“城市名稱:城市代碼”的字典,或者由元組(城市名稱,城市代碼)組成的列表,供爬取時遍歷。考慮到正則提取時,構造元組更便捷,就不做成字典了。
def getCity():
html = reqs.get('https://tianqi.2345.com/js/citySelectData.js').content
text = html.decode('gbk')
city = re.findall('([1-5]\d{4})\-[A-Z]\s(.*?)\-\d{5}',text) #只提取了地級市及以上城市的名稱和代碼,5以上的是縣級市
city = list(set(city)) #去掉重復城市數據
print('城市列表獲取成功')
return city
接下來是構造url列表,感謝教材主編的提醒,這里避免了一個大坑。原來2017年之前的url結構和后面的不一樣,在這里照搬了主編的構造方法:
def getUrls(cityCode):
urls = []
for year in range(2011,2020):
if year <= 2016:
for month in range(1, 13):
urls.append('https://tianqi.數字.com/t/wea_history/js/%s_%s%s.js' % (cityCode,year, month))
else:
for month in range(1,13):
if month<10:
urls.append('https://tianqi.數字.com/t/wea_history/js/%s0%s/%s_%s0%s.js' %(year,month,cityCode,year,month))
else:
urls.append('https://tianqi.數字.com/t/wea_history/js/%s%s/%s_%s%s.js' %(year,month,cityCode,year,month))
return urls
接下來定義一個爬取頁面的函數getHtml(),這個是常規操作,用requests模塊就行了:
def getHtml(url):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1',
'Referer': '******'}
request = reqs.get(url,headers = header)
text = request.content.decode('gbk') #經試解析,這里得用gbk模式
time.sleep(random.randint(1,3)) #隨機暫停,減輕服務器壓力
return text
然后就是重點部分了,數據解析與提取。
試了試json解析,發現效果不好,因為頁面文本里面含雜質。
還是用正則表達式吧,能夠提取有效數據,盡可能少浪費機器時間。
2016年開始的數據和之前年份不一樣,多了PM2.5污染物情況,因此構造正則表達式時,還不能用偷懶模式。
str1 = "{ymd:'(.*?)',bWendu:'(.*?)℃',yWendu:'(.*?)℃',tianqi:'(.*?)',fengxiang:'(.*?)',fengli:'(.*?)',aqi:'(.*?)',aqiInfo:'(.*?)',aqiLevel:'(.*?)'.*?}"
str2 = "{ymd:'(.*?)',bWendu:'(.*?)℃',yWendu:'(.*?)℃',tianqi:'(.*?)',fengxiang:'(.*?)',fengli:'(.*?)'.*?}"
#這個就是偷懶模式,取出來的內容直接存入元組中
如果嚴格以2016年為界,用一下偷懶模式還行,但本人在這里遇坑了,原來個別城市的污染物信息是時有時無的,搞不清在某年某月的某天就出現了,因此還得構造一個通用版的,把數據都提出來,再把無用的字符去掉。
def getDf(url):
html = getHtml(url)
pa = re.compile(r'{(ymd.+?)}') #用'{ymd'打頭,把不是每日天氣的其它數據忽略掉
text = re.findall(pa,html)
list0 = []
for item in text:
s = item.split(',') #分割成每日數據
d = [i.split(':') for i in s] #提取冒號前后的數據名稱和數據值
t = {k:v.strip("'").strip('℃') for k,v in d} #用數據名稱和數據值構造字典
list0.append(t)
df = pd.DataFrame(list0) #加入pandas列表中,便于保存
return df
數據的保存,這里選擇了sqlite3輕便型數據庫,可以保存成db文件:
def work(city,url):
con =sql.connect('d:\\天氣.db')
try:
df = getDf(url)
df.insert(0,'城市名稱',city) #新增一列城市名稱
df.to_sql('total', con, if_exists='append', index=False)
print(url,'下載完成')
except Exception as e:
print("出現錯誤:\n",e)
finally:
con.commit()
con.close()
在這里還有一個小坑,第一次連接數據庫文件時,如果文件不存在,會自動添加,后續在寫入數據時,如果數據中新增了字段,寫入時會報錯。可以先把數據庫文件字段都設置好,但這樣太累,所以本人又搞了個偷懶的方式,即先傳入一個2019年某月的單個url搞一下,自動添加好字段,后面再寫入時就沒問題了。本人覺得這個應該還有更佳的解決辦法,目前還在挖掘中。
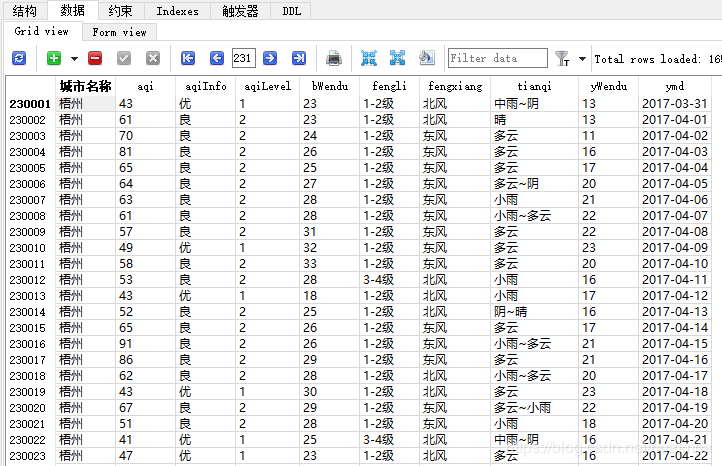
數據保存后的狀態如下:
本來考慮過用多線程爬蟲,想想又覺得既然人家沒有設置反爬措施,咱們也不能太不厚道了,就單線程吧。
最終爬了334個城市,100多萬條數據。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





