溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
前言
在云平臺的日常運維工作中,有很多故障排查和數據核對的場景,為了給全線運維人員(含部分開發和運營分析人員)提供現網數據的實時查詢,我們使用MySQL和開源工具otter搭建了一套數據查詢和管理系統,可以查詢平臺各資源池現網當前的數據。并與現網保持準實時同步(秒級延時)。
查詢模塊的主要組件是MySQL,納管線上業務系統的核心數據庫,用戶使用頻次極高,此臺MySQL中的部分核心數據還作為其他資源池的源數據,實時同步給異地機房。負責數據實時同步的otter管理節點與MySQL部署在同一物理機上,是云平臺所有資源池中查詢模塊的中樞節點。
首先,介紹一下開源工具Otter(內容引自GitHub)
Otter是由阿里提供的基于數據庫增量日志解析,準實時同步到本機房或異地機房MySQL數據庫的一個分布式數據庫同步系統,工作原理如下:
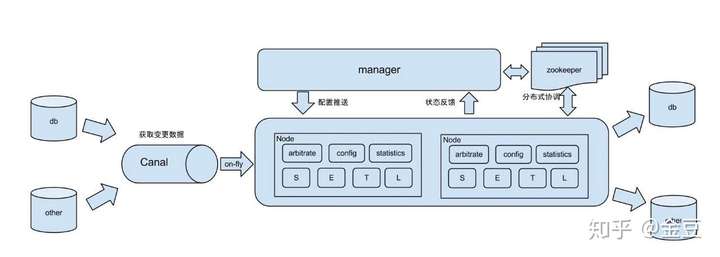
db:數據源以及需要同步到的庫;
Canal:用戶獲取數據庫增量日志;
manager:配置同步規則設置數據源同步源等;
zookeeper:協調node進行協調工作;
node:負責任務處理處理接受到的部分同步工作。
一、Otter的特性
1、純JAVA開發,占時資源比較高
2、基于Canal獲取數據庫增量日志數據,Canal是阿里另一款開源產品
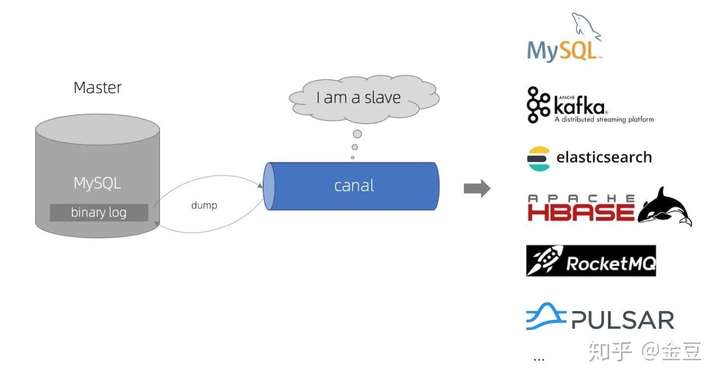
下面是Canal的原理圖:
已經為大家精心準備了大數據的系統學習資料,從Linux-Hadoop-spark-......,需要的小伙伴可以點擊
基于MySQL主備復制原理:
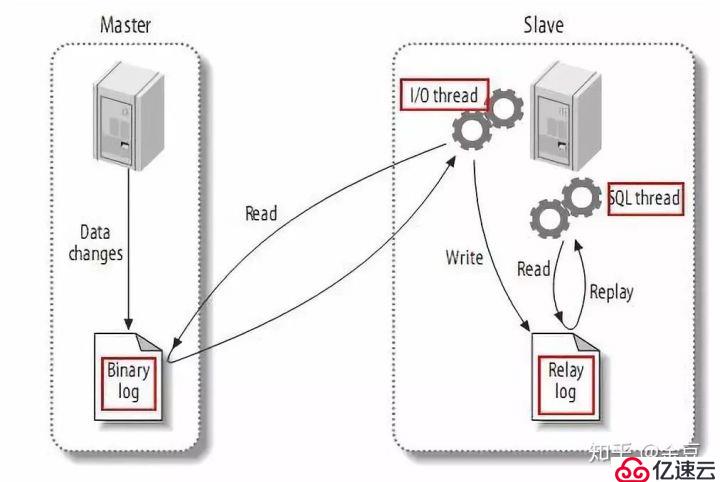
MySQL master 將數據變更寫入二進制日志( binary log, 其中記錄叫做二進制日志事件binary log events,可以通過 show binlog events 進行查看);
MySQL slave 將 master 的 binary log events 拷貝到它的中繼日志(relay log);
MySQL slave 重放 relay log 中事件,將數據變更反映它自己的數據。
Canal工作原理:
Canal 模擬 MySQL slave 的交互協議,偽裝自己為 MySQL slave ,向 MySQL master 發送dump 協議;
MySQL master 收到 dump 請求,開始推送 binary log 給 slave (即 canal );
Canal 解析 binary log 對象(原始為 byte 流)。
3、典型管理系統架構,manager(web管理)+node(工作節點)
1)manager運行時推送同步配置到node節點,負責配置監控
2)node節點將同步狀態反饋到manager上,負責處理任務
4、基于zookeeper,解決分布式狀態調度的,允許多node節點之間協同工作
5、使用aria2多線程傳輸技術,對網絡依賴帶寬依賴較低
二、Otter能解決什么問題
1、異構庫同步
MySQL -> MySQL/Oracle。(目前開源版本只支持MySQL增量,目標庫可以是MySQL或者Oracle,取決于Canal的功能)
2、單機房同步 (數據庫之間RTT < 1ms)
數據庫版本升級;
數據表遷移;
異步二級索引。
3、異地機房同步(是Otter最大的亮點之一,可以解決國際化問題把數據從國內同步到國外提供用戶使用,在國內場景可以做到數據多機房容災)
機房容災
4、雙向同步(雙向同步是在數據同步中最難搞的一種場景,Otter可以很好的應對這種場景,Otter有避免回環算法和數據一致性算法兩種特性,保證雙A機房模式下,數據保證最終一致性)
1)避免回環算法 (通用的解決方案,支持大部分關系型數據庫)
2)數據一致性算法 (保證雙A機房模式下,數據保證最終一致性,亮點)
5、文件同步
站點鏡像 (進行數據復制的同時,復制關聯的圖片,比如復制產品數據,同時復制產品圖片)
單機房復制示意圖:
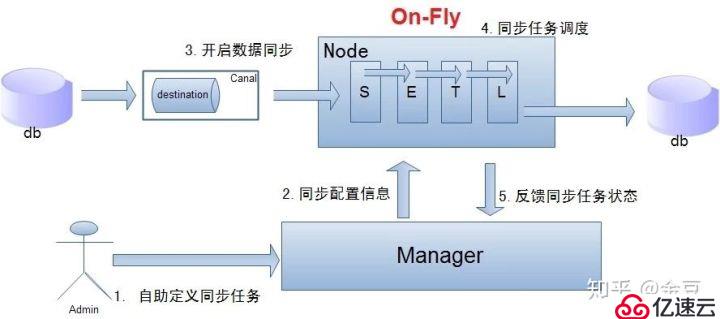
說明:
數據on-Fly,盡可能不落地,更快的進行數據同步. (開啟node loadBalancer算法,如果Node節點S+ETL落在不同的Node上,數據會有個網絡傳輸過程);
node節點可以有failover / loadBalancer。
異地機房復制示意圖:
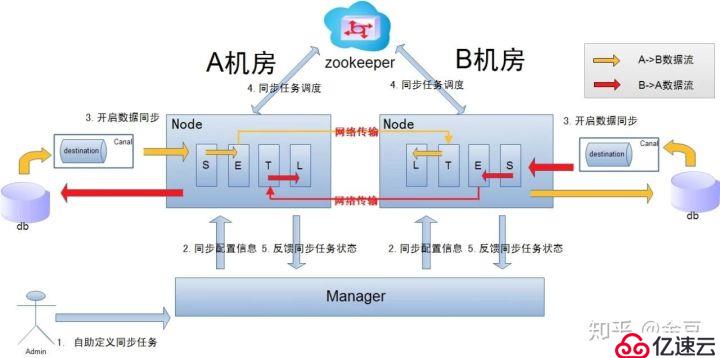
說明:
數據涉及網絡傳輸,S/E/T/L幾個階段會分散在2個或者更多Node節點上,多個Node之間通過zookeeper進行協同工作 (一般是Select和Extract在一個機房的Node,Transform/Load落在另一個機房的Node);
node節點可以有failover / loadBalancer. (每個機房的Node節點,都可以是集群,一臺或者多臺機器)。
關于Otter的調度模型、數據入庫算法、一致性、高可用性和擴展性等內容,可以登錄GitHub了解。
已經為大家精心準備了大數據的系統學習資料,從Linux-Hadoop-spark-......,需要的小伙伴可以點擊
里面有詳細的介紹,本文不再贅述,下面重點說明一下otter的安裝和使用。
三、安裝部署
移動云業務需要數據匯總,需將多個主數據庫同步匯總到一個從數據庫中,方便數據統計分析。Otter中間件則滿足了此需求,相對比多源復制,更加靈活和可塑性。
前面簡單介紹了Otter的基本信息,下面開始搭建一個Otter環境,因為一個Otter需要Manage+node+數據庫還有很多的依賴,這里我們先來搭建Otter的管理服務器Manager。
1、環境準備
1)阿里軟件
Otter(manager、node)軟件:https://github.com/alibaba/otter/releases
Manager數據庫初始化腳本:https://raw.githubusercontent.com/alibaba/otter/master/manager/deployer/src/main/resources/sql/otter-manager-schema.sql
2)集群
Zookeeper:http://download.csdn.net/download/jxplus/9451794
3)JAVA
JDK:測試環境使用yum安裝1.6以上版本
4)數據庫
Mysql5.7:http://dev.mysql.com/downloads/mysql/
5)操作系統
CentOS 7.1.1503 (Core):https://www.centos.org/download/
版本信息

2、軟件安裝
1)操作系統安裝
2)java jdk1.6
安裝完成操作系統后,使用yum安裝jdk1.6以上版本(含1.6)
yum -y install java-1.6.0-openjdk.x86_64
3)安裝MySQL數據庫
4)安裝集群軟件ZooKeeper
下載安裝包后解壓即可,不需要編譯安裝。然后進行配置:
① 修改tickTime、clientPort、dataDir參數
vim /zookeeper-3.4.8/conf/zoo.cfg
tickTime :時長單位為毫秒,為zk使用的基本時間度量單位。例如,1 * tickTime是客戶端與zk服務端的心跳時間,2 * tickTime是客戶端會話的超時時間。
tickTime的默認值為2000毫秒,更低的tickTime值可以更快地發現超時問題,但也會導致更高的網絡流量(心跳消息)和更高的CPU使用率(會話的跟蹤處理)。
clientPort :zk服務進程監聽的TCP端口,默認情況下,服務端會監聽2181端口。
dataDir :無默認配置,必須配置,用于配置存儲快照文件的目錄。
② 執行下面命令啟動server
cd /zookeeper-3.4.8/bin/?
./zkServer.sh start
向AI問一下細節
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





