溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
方法一:同步操作
1.pipelines.py文件(處理數據的python文件)
import pymysql class LvyouPipeline(object): def __init__(self): # connection database self.connect = pymysql.connect(host='XXX', user='root', passwd='XXX', db='scrapy_test') # 后面三個依次是數據庫連接名、數據庫密碼、數據庫名稱 # get cursor self.cursor = self.connect.cursor() print("連接數據庫成功") def process_item(self, item, spider): # sql語句 insert_sql = """ insert into lvyou(name1, address, grade, score, price) VALUES (%s,%s,%s,%s,%s) """ # 執行插入數據到數據庫操作 self.cursor.execute(insert_sql, (item['Name'], item['Address'], item['Grade'], item['Score'], item['Price'])) # 提交,不進行提交無法保存到數據庫 self.connect.commit() def close_spider(self, spider): # 關閉游標和連接 self.cursor.close() self.connect.close()
2.配置文件中
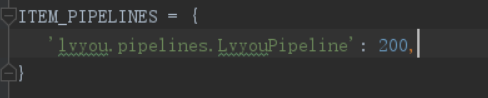
方式二 異步儲存
pipelines.py文件:
通過twisted實現數據庫異步插入,twisted模塊提供了 twisted.enterprise.adbapi
1. 導入adbapi
2. 生成數據庫連接池
3. 執行數據數據庫插入操作
4. 打印錯誤信息,并排錯
import pymysql
from twisted.enterprise import adbapi
# 異步更新操作
class LvyouPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings): # 函數名固定,會被scrapy調用,直接可用settings的值
"""
數據庫建立連接
:param settings: 配置參數
:return: 實例化參數
"""
adbparams = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
password=settings['MYSQL_PASSWORD'],
cursorclass=pymysql.cursors.DictCursor # 指定cursor類型
)
# 連接數據池ConnectionPool,使用pymysql或者Mysqldb連接
dbpool = adbapi.ConnectionPool('pymysql', **adbparams)
# 返回實例化參數
return cls(dbpool)
def process_item(self, item, spider):
"""
使用twisted將MySQL插入變成異步執行。通過連接池執行具體的sql操作,返回一個對象
"""
query = self.dbpool.runInteraction(self.do_insert, item) # 指定操作方法和操作數據
# 添加異常處理
query.addCallback(self.handle_error) # 處理異常
def do_insert(self, cursor, item):
# 對數據庫進行插入操作,并不需要commit,twisted會自動commit
insert_sql = """
insert into lvyou(name1, address, grade, score, price) VALUES (%s,%s,%s,%s,%s)
"""
self.cursor.execute(insert_sql, (item['Name'], item['Address'], item['Grade'], item['Score'],
item['Price']))
def handle_error(self, failure):
if failure:
# 打印錯誤信息
print(failure)
注意:
1、python 3.x 不再支持MySQLdb,它在py3的替代品是: import pymysql。
2、報錯pymysql.err.ProgrammingError: (1064, ……
原因:當item['quotes']里面含有引號時,可能會報上述錯誤
解決辦法:使用pymysql.escape_string()方法
例如:
sql = """INSERT INTO video_info(video_id, title) VALUES("%s","%s")""" % (video_info["id"],pymysql.escape_string(video_info["title"]))
3、存在中文的時候,連接需要添加charset='utf8',否則中文顯示亂碼。
4、每執行一次爬蟲,就會將數據追加到數據庫中,如果多次的測試爬蟲,就會導致相同的數據不斷累積,怎么實現增量爬取?
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





