溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一 引入
解釋器在執行到定義變量的語法時,會申請內存空間來存放變量的值,而內存的容量是有限的,這就涉及到變量值所占用內存空間的回收問題,當一個變量值沒有用了(簡稱垃圾)就應該將其占用的內存給回收掉,那什么樣的變量值是沒有用的呢?
由于變量名是訪問到變量值的唯一方式,所以當一個變量值不再關聯任何變量名時,我們就無法再訪問到該變量值了,該變量值就是沒有用的,就應該被當成一個垃圾回收。
毫無疑問,內存空間的申請與回收是非常耗費精力的事情,而且存在很大的危險性,稍有不慎就有可能引發內存溢出問題,好在Cpython解釋器提供了自動的垃圾回收機制來幫我們 解決了這件事。
二、什么是垃圾回收機制?
垃圾回收機制(簡稱GC)是Python解釋器自帶一種機,專門用來回收不可用的變量值所占用的內存空間
三、為什么要用垃圾回收機制?
程序運行過程中會申請大量的內存空間,而對于一些無用的內存空間如果不及時清理的話會導致內存使用殆盡(內存溢出),導致程序崩潰,因此管理內存是一件重要且繁雜的事情,而python解釋器自帶的垃圾回收機制把程序員從繁雜的內存管理中解放出來。
四、垃圾回收機制原理分析
Python的GC模塊主要運用了“引用計數”(reference counting)來跟蹤和回收垃圾。在引用計數的基礎上,還可以通過“標記-清除”(mark and sweep)解決容對象可能產生的循環引用的問題,并且通過“分代回收”(generation collection)以空間換取時間的方式來進一步提高垃圾回收的效率。
4.1、什么是引用計數?
引用計數就是:變量值被變量名關聯的次數
如:age=18
變量值18被關聯了一個變量名age,稱之為引用計數為1
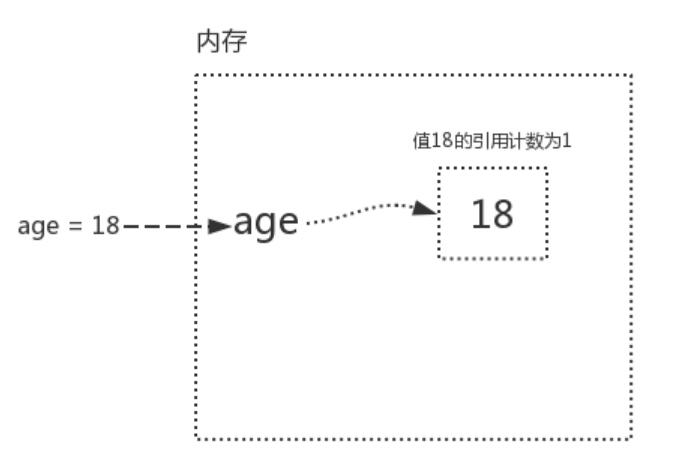
引用計數增加:
age=18 (此時,變量值18的引用計數為1)
m=age (把age的內存地址給了m,此時,m,age都關聯了18,所以變量值18的引用計數為2)
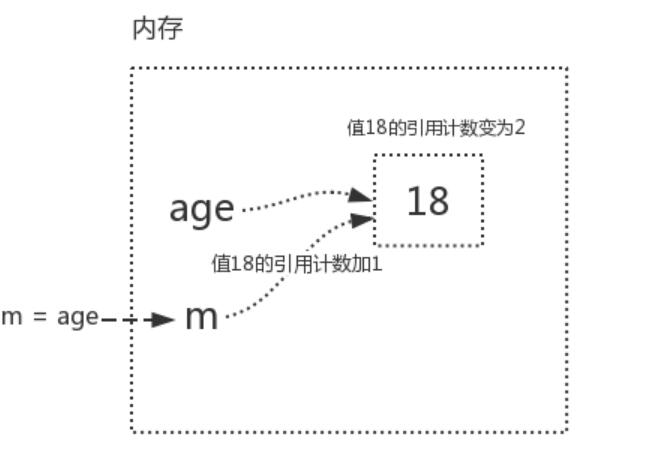
引用計數減少:
age=10(名字age先與值18解除關聯,再與3建立了關聯,變量值18的引用計數為1)
del m(del的意思是解除變量名x與變量值18的關聯關系,此時,變量18的引用計數為0)
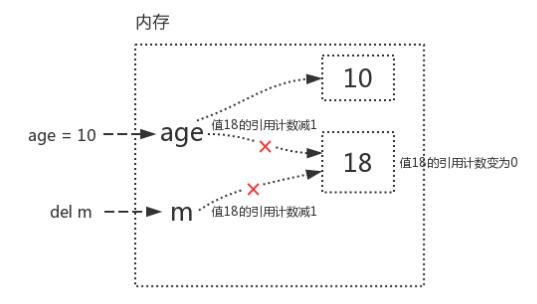
值18的引用計數一旦變為0,其占用的內存地址就應該被解釋器的垃圾回收機制回收
4.2、引用計數擴展閱讀
變量值被關聯次數的增加或減少,都會引發引用計數機制的執行(增加或減少值的引用計數),這存在明顯的效率問題。
如果說執行效率還僅僅是引用計數機制的一個軟肋的話,那么很不幸,引用計數機制還存在著一個致命的弱點,即循環引用(也稱交叉引用)
# 如下我們定義了兩個列表,簡稱列表1與列表2,變量名l1指向列表1,變量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用計數變為1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用計數變為1
>>> l1.append(l2) # 把列表2追加到l1中作為第二個元素,列表2的引用計數變為2
>>> l2.append(l1) # 把列表1追加到l2中作為第二個元素,列表1的引用計數變為2
# l1與l2之間有相互引用
# l1 = ['xxx'的內存地址,列表2的內存地址]
# l2 = ['yyy'的內存地址,列表1的內存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][
循環引用會導致:值不再被任何名字關聯,但是值的引用計數并不會為0,應該被回收但不能被回收,什么意思呢?試想一下,請看如下操作
>>> del l1 # 列表1的引用計數減1,列表1的引用計數變為1
>>> del l2 # 列表2的引用計數減1,列表2的引用計數變為1
此時,只剩下列表1與列表2之間的相互引用,兩個列表的引用計數均不為0,但兩個列表不再被任何其他對象關聯,沒有任何人可以再引用到它們,所以它倆占用內存空間應該被回收,但由于相互引用的存在,每一個對象的引用計數都不為0,因此這些對象所占用的內存永遠不會被釋放,所以循環引用是致命的,這與手動進行內存管理所產生的內存泄露毫無區別。所以Python引入了“標記-清除” 與“分代回收”來分別解決引用計數的循環引用與效率低的問題
4.2.1 標記-清除
容器對象(比如:list,set,dict,class,instance)都可以包含對其他對象的引用,所以都可能產生循環引用。而“標記-清除”計數就是為了解決循環引用的問題。
在了解標記清除算法前,我們需要明確一點,關于變量的存儲,內存中有兩塊區域:堆區與棧區,在定義變量時,變量名與值內存地址的關聯關系存放于棧區,變量值存放于堆區,內存管理回收的則是堆區的內容,詳解如下圖,定義了兩個變量x = 10、y = 20
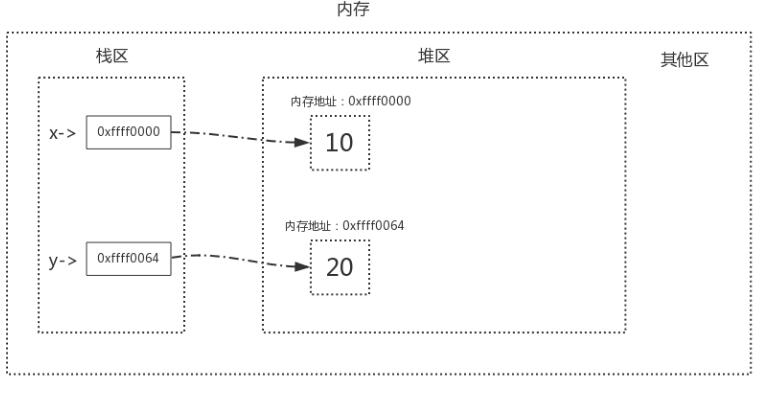
當我們執行x=y時,內存中的棧區與堆區變化如下
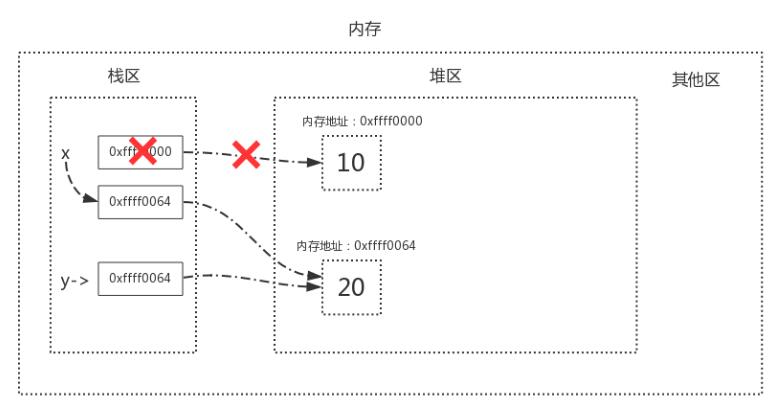
標記/清除算法的做法是當應用程序可用的內存空間被耗盡的時,就會停止整個程序,然后進行兩項工作,第一項則是標記,第二項則是清除
#1、標記
標記的過程其實就是,遍歷所有的GC Roots對象(棧區中的所有內容或者線程都可以作為GC Roots對象),然后將所
有GC Roots的對象可以直接或間接訪問到的對象標記為存活的對象,其余的均為非存活對象,應該被清除。
#2、清除
清除的過程將遍歷堆中所有的對象,將沒有標記的對象全部清除掉。
直接引用指的是從棧區出發直接引用到的內存地址,間接引用指的是從棧區出發引用到堆區后再進一步引用到的內存地址,以我們之前的兩個列表l1與l2為例畫出如下圖像
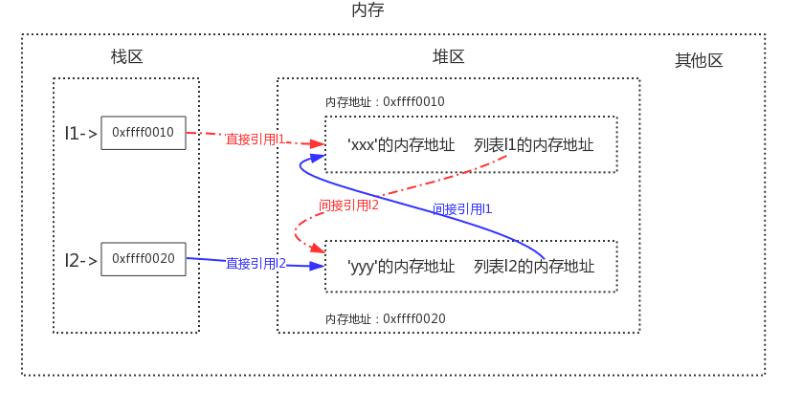
當我們同時刪除l1與l2時,會清理到棧區中l1與l2的內容
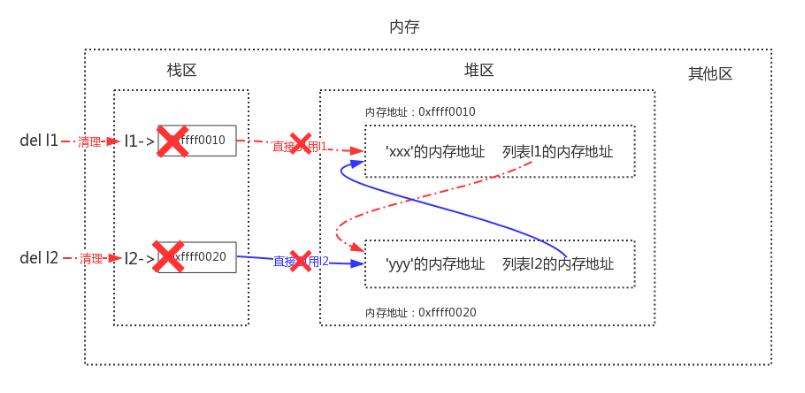
這樣在啟用標記清除算法時,發現棧區內不再有l1與l2(只剩下堆區內二者的相互引用),于是列表1與列表2都沒有被標記為存活,二者會被清理掉,這樣就解決了循環引用帶來的內存泄漏問題
4.2.2 分代回收
背景:
基于引用計數的回收機制,每次回收內存,都需要把所有對象的引用計數都遍歷一遍,這是非常消耗時間的,于是引入了分代回收來提高回收效率,分代回收采用的是用“空間換時間”的策略。
分代:
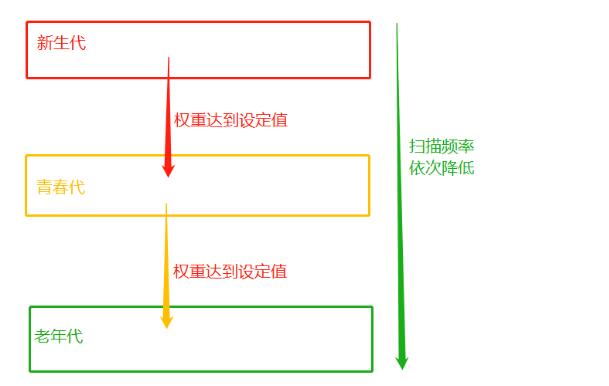
分代回收的核心思想是:在歷經多次掃描的情況下,都沒有被回收的變量,gc機制就會認為,該變量是常用變量,gc對其掃描的頻率會降低,具體實現原理如下:
分代指的是根據存活時間來為變量劃分不同等級(也就是不同的代)
新定義的變量,放到新生代這個等級中,假設每隔1分鐘掃描新生代一次,如果發現變量依然被引用,那么該對象的權重(權重本質就是個整數)加一,當變量的權重大于某個設定得值(假設為3),會將它移動到更高一級的青春代,青春代的gc掃描的頻率低于新生代(掃描時間間隔更長),假設5分鐘掃描青春代一次,這樣每次gc需要掃描的變量的總個數就變少了,節省了掃描的總時間,接下來,青春代中的對象,也會以同樣的方式被移動到老年代中。也就是等級(代)越高,被垃圾回收機制掃描的頻率越低
回收:
回收依然是使用引用計數作為回收的依據
雖然分代回收可以起到提升效率的效果,但也存在一定的缺點:
例如一個變量剛剛從新生代移入青春代,該變量的綁定關系就解除了,該變量應該被回收,但青春代的掃描頻率低于新生代,所以該變量的回收就會被延遲。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持億速云。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





