溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據庫往往是系統中的性能瓶頸,所以通常在系統設計中會引入各種各樣的緩存機制,以避免頻繁訪問數據庫。另外,數據庫由于其重要性,高可用要求也是避免不了的,因為一旦數據庫掛了基本上整個系統也就不能使用了。
而以上這些常見問題都是單點數據庫帶來的限制,為了解決這些問題,達到高性能、高可用的目的,我們就需要在系統架構設計中采用數據庫集群方案。
既然單點數據庫存在性能問題,那么有沒有實際數據呢?下面我們就來對單點數據庫進行一個性能測試,看看其并發極限大概是多少。我這里使用了一臺2核2G的云服務,mysql版本為8.0.18。
mysql自帶了一個性能測試工具:mysqlslap,我們可以使用該工具進行測試,具體的測試參數如下:
[root@localhost ~]# mysqlslap -hlocalhost -uroot -pyour_password -P3306 --concurrency=500 --iterations=1 --auto-generate-sql --auto-generate-sql-load-type=mixed --auto-generate-sql-add-autoincrement --engine=innodb --number-of-queries=500主要參數說明:
| 參數 | 說明 |
|---|---|
--concurrency |
并發數量,即模擬的客戶端數量 |
--iterations |
執行多少次該測試 |
--auto-generate-sql |
使用系統自己生成的SQL腳本來測 |
--auto-generate-sql-load-type |
要測試的是讀還是寫還是兩者混合的(取值:read, write, update, mixed) |
--auto-generate-sql-add-autoincrement |
將自增的列添加到自動生成的表中 |
--engine |
要測試的存儲引擎 |
--number-of-queries |
每個客戶端的訪問次數,該數值除以并發數量就是每個客戶端的訪問次數,在本例中:500 / 500 = 1 |
這里我分別進行了不同量級的測試,在并發500、1000和5000個連接時,數據庫還可以正常處理,沒有太大問題:
# 500個并發連接
Benchmark
Running for engine innodb
Average number of seconds to run all queries: 0.391 seconds
Minimum number of seconds to run all queries: 0.391 seconds
Maximum number of seconds to run all queries: 0.391 seconds
Number of clients running queries: 500
Average number of queries per client: 1
# 1000個并發連接
Benchmark
Running for engine innodb
Average number of seconds to run all queries: 0.802 seconds
Minimum number of seconds to run all queries: 0.802 seconds
Maximum number of seconds to run all queries: 0.802 seconds
Number of clients running queries: 1000
Average number of queries per client: 1
# 5000個并發連接
Benchmark
Running for engine innodb
Average number of seconds to run all queries: 3.884 seconds
Minimum number of seconds to run all queries: 3.884 seconds
Maximum number of seconds to run all queries: 3.884 seconds
Number of clients running queries: 5000
Average number of queries per client: 1但在測試1w個并發連接時,數據庫就開始報無法連接的錯誤了:
由該測試案例可知,普通的單節點數據庫性能瓶頸大概在1w個并發連接左右。當然這里的測試結果與機器的硬件差異有關,只是提供一個參考。
上一小節介紹了單點數據庫存在的問題,以及進行了一個簡單的性能測試。為了應對這些問題,我們需要將單點數據庫向集群轉變。
目前存在許多的數據庫集群方案,而這些方案中也沒有哪個好那個壞,只有適合的才是好的。本小節則介紹一下主流的方案之一:PXC集群方案,其架構圖大致如下: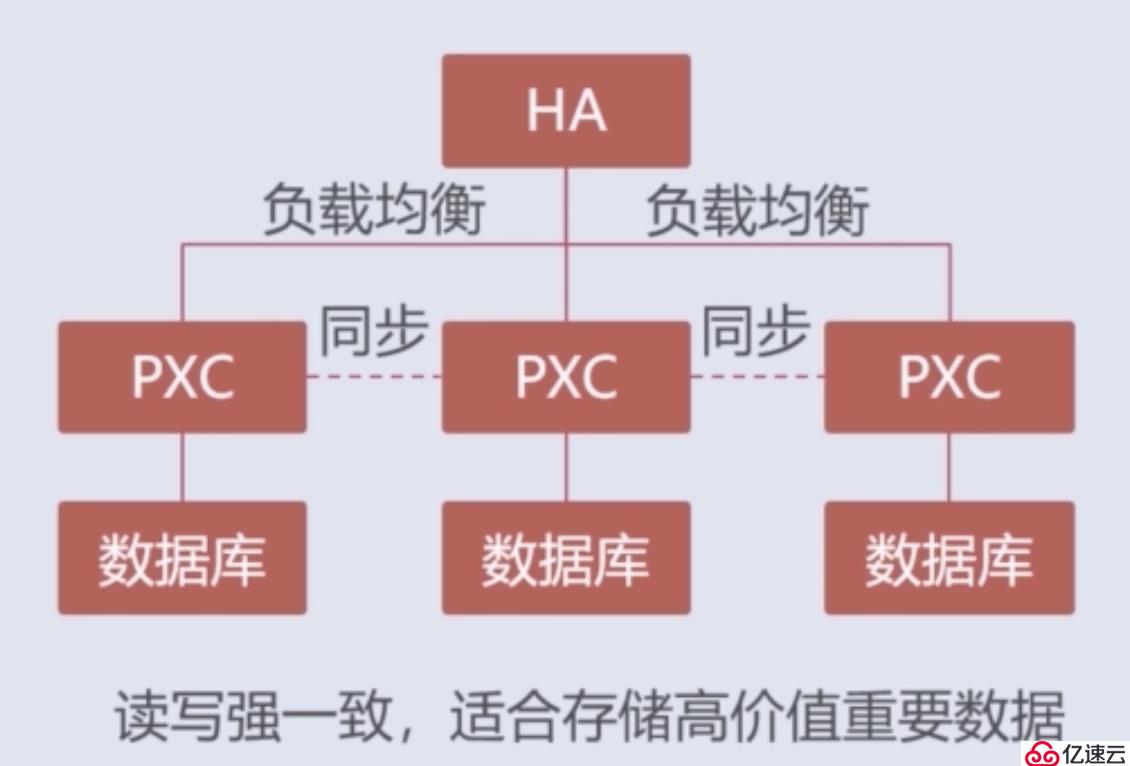
上圖只是PXC集群最基礎的架構,所以還有優化的余地。我們都知道mysql的單表數據處理的性能極限在2千萬左右,當數據達到這個量級時,mysql的處理性能就會很低下了。而上圖中每個PXC節點都會進行數據的同步,所以當每個節點的數據量級都達到2千萬時,整個集群的性能就會降低。
這時就需要增加多一個集群,并且這兩個集群之間的數據是不進行同步的。為了讓不同的集群存儲不同的數據,就得引入Mycat這種數據庫中間件將數據進行切分,讓數據可以在不同的集群上進行讀寫,分散存儲壓力。在這個場景下,一個集群稱為一個數據分片。如圖: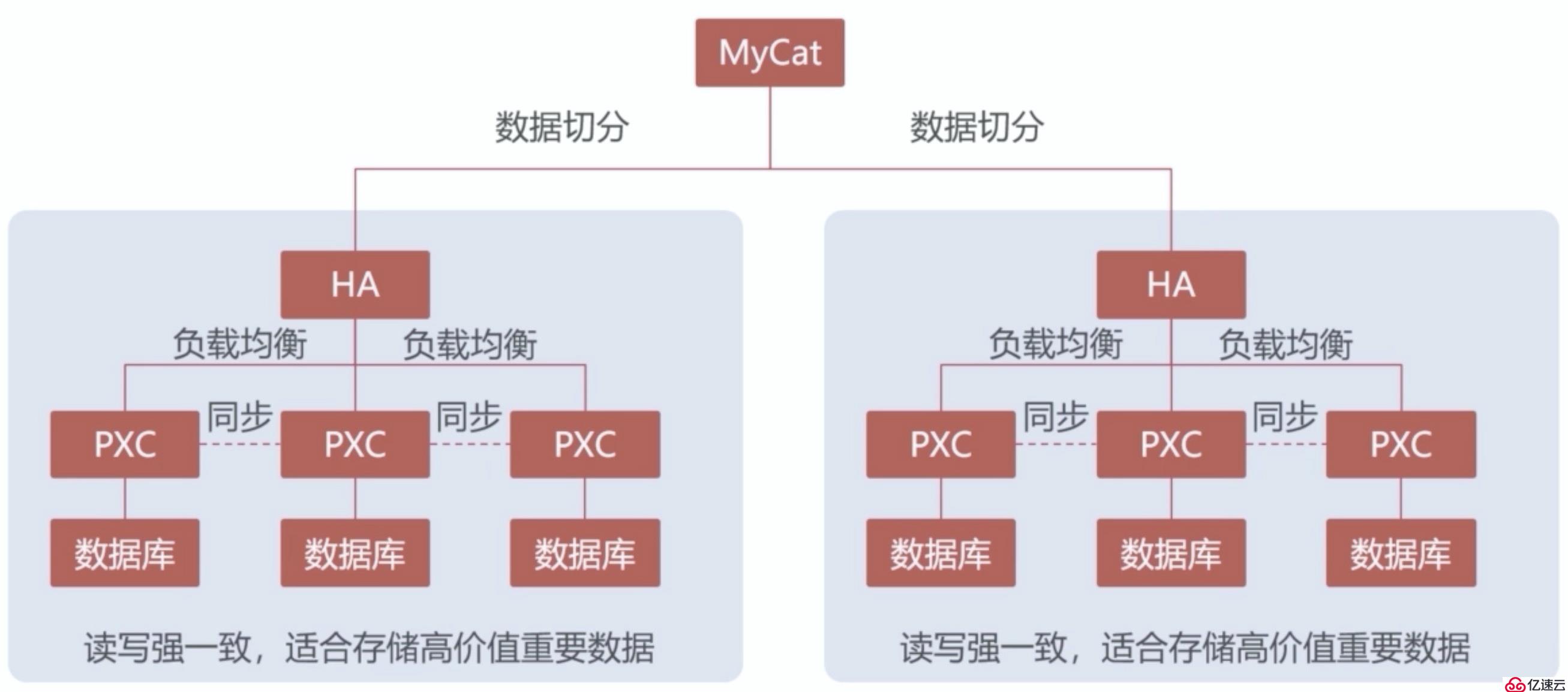
我們知道數據庫數據的一致性和持久性是通過事務來保證的,而PXC集群的強一致性也是采用了事務,只不過這個事務是分布式事務。
客戶端在寫入數據完成后,同樣需要提交一個事務,在事務內節點之間會進行數據的同步復制。該事務會作用到集群內的所有節點上,保證所有節點要么全寫入成功,要么全寫入失敗。這里用一個時序圖表達一下大致流程: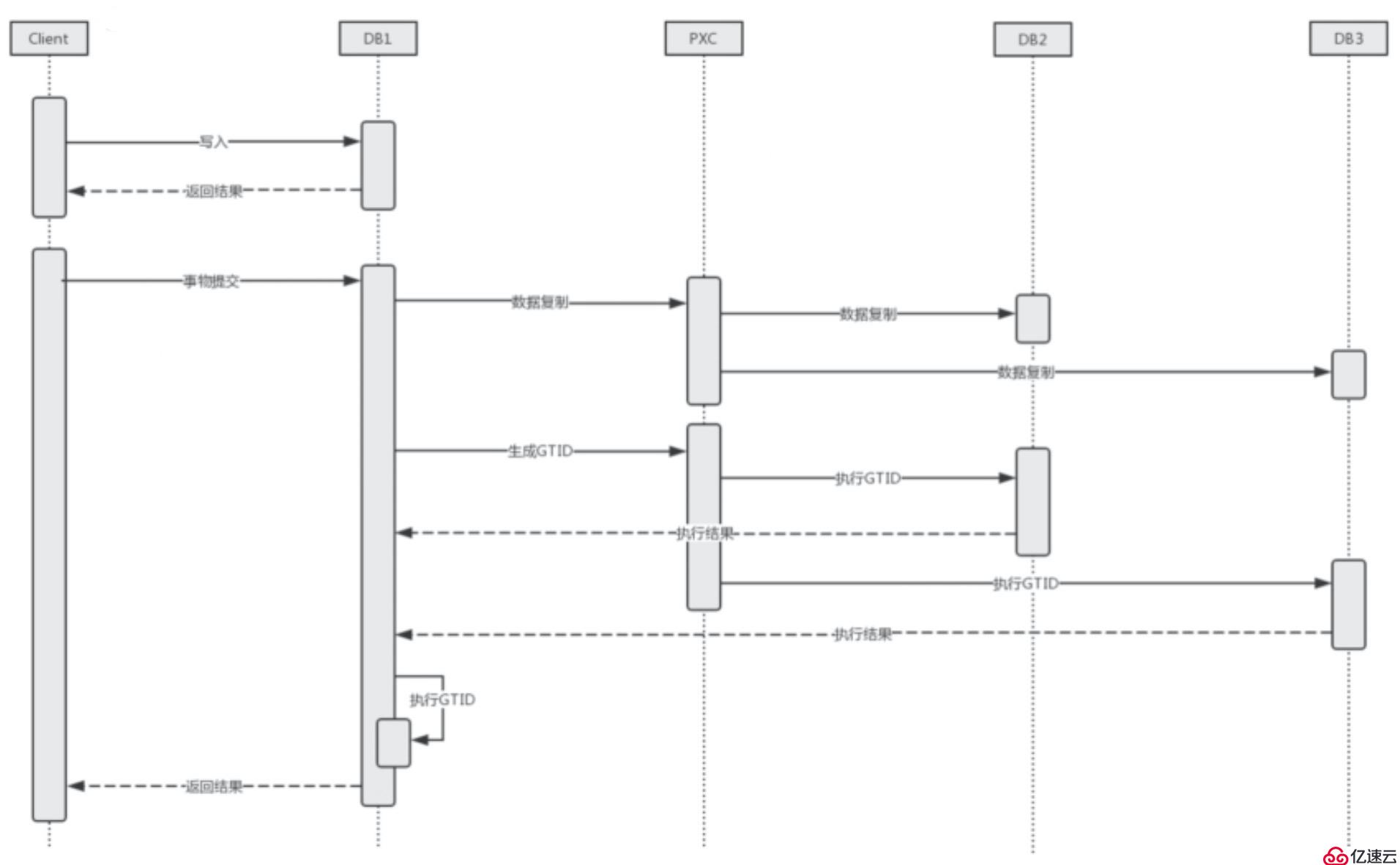
搭建PXC集群需要注意的事項:
說了那么多,我們還沒介紹PXC是個啥玩意呢。PXC是Percona XtraDB Cluster的縮寫,PXC是基于mysql自帶的Galera集群技術,將不同的mysql實例連接起來,實現的多主集群。在PXC集群中每個mysql節點都是可讀可寫的,也就是主從概念中的主節點,不存在只讀的節點。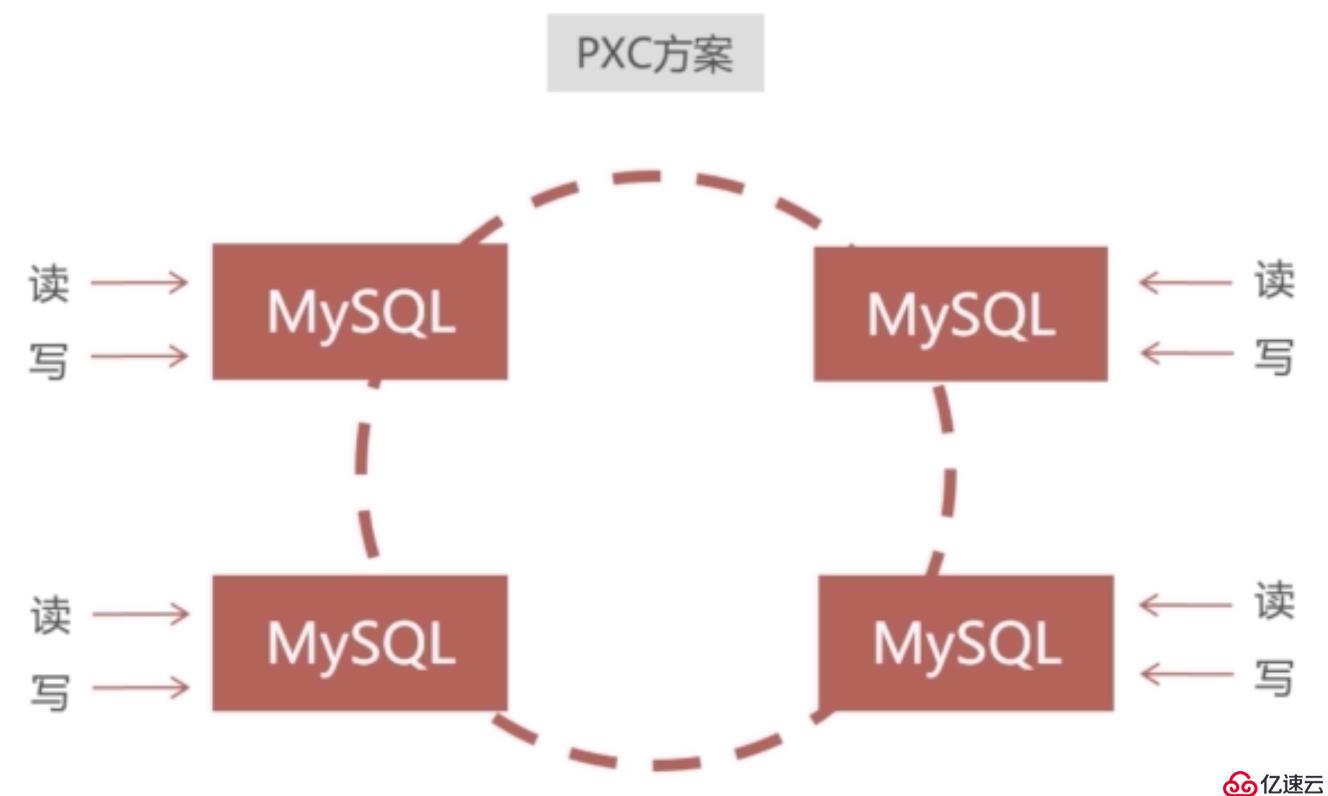
PXC可以集群任何mysql的衍生版本,例如MariaDB和Percona Server。由于Percona Server的性能最接近于mysql企業版,性能相對于標準版的mysql有顯著的提升,并且對mysql基本兼容。所以在搭建PXC集群時,通常建議基于Percona Server進行搭建。
PXC集群的數據強一致性是以犧牲性能為代價的,因為客戶端需要等待所有的節點寫入數據。而與之相反的一種集群方案就是本小節要介紹的Replication集群。該方案不犧牲性能,但不具有數據強一致性,正可謂魚和熊掌不可兼得。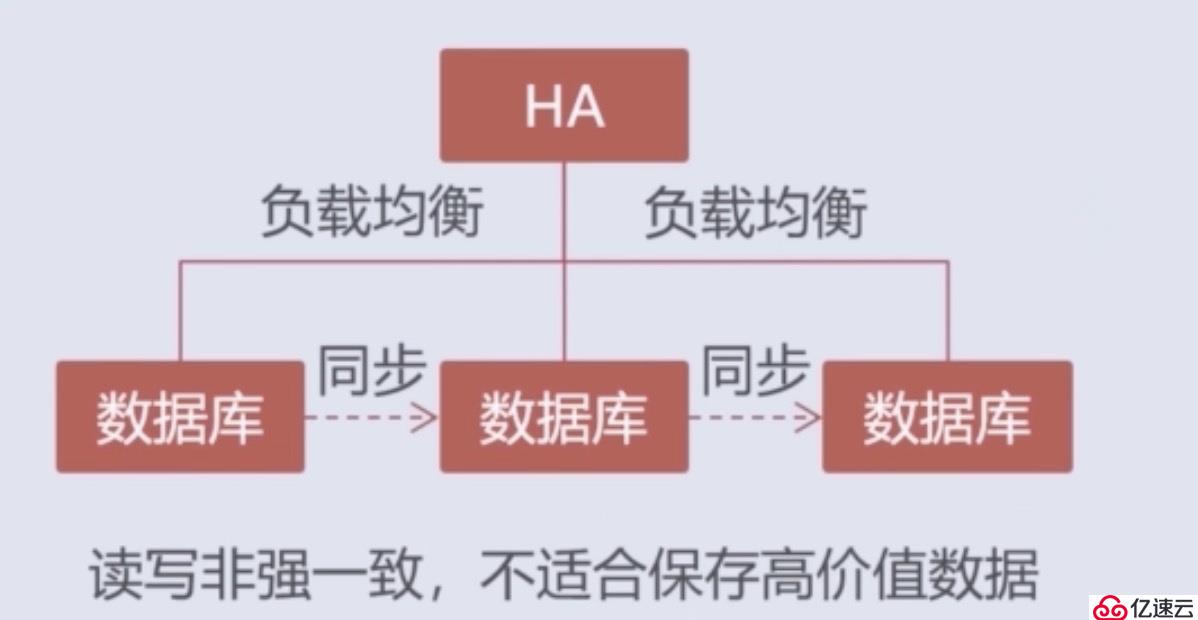
所謂讀寫非強一致的意思就是在A節點成功寫入數據,并提交了事務。但在B節點上進行讀取時,可能會讀取不到寫入的數據。
因為這里提交的事務只是該節點的本地事務,只能保證數據成功寫入了該節點,而不保證數據成功寫入整個集群內的節點。當該節點與其他節點進行數據同步時,可能會由于種種原因沒有成功同步數據,從而導致在其他節點上讀不到該數據。
所以該集群方案就不適合保存高價值的數據,但對于非高價值的數據,又對讀寫性能要求高的,就適合采用該集群方案。例如,用戶行為日志、操作日志及商品描述等這類非重要的數據。
同樣的,上圖只是Replication集群最基礎的架構,也需要在數據量達到一定規模時采用Mycat對數據進行分片處理。如圖: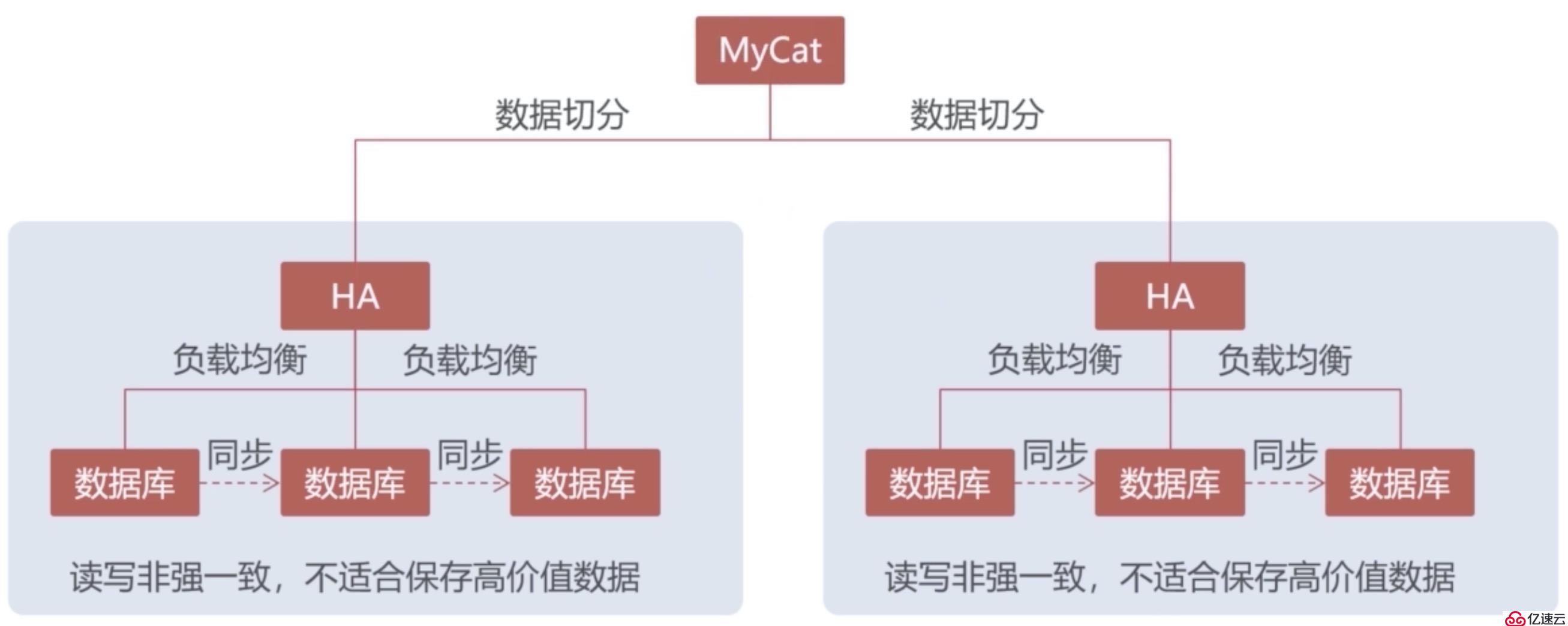
實際上,在大型的系統架構中,往往不是單獨采用某一種特定的集群方案,而是多種方案進行結合。例如,PXC集群和Replication集群就可以結合使用,讓PXC集群存儲高價值數據,Replication集群存儲低價值數據。然后采用Mycat等數據庫中間件來完成集群之間的數據分片及管理,如圖: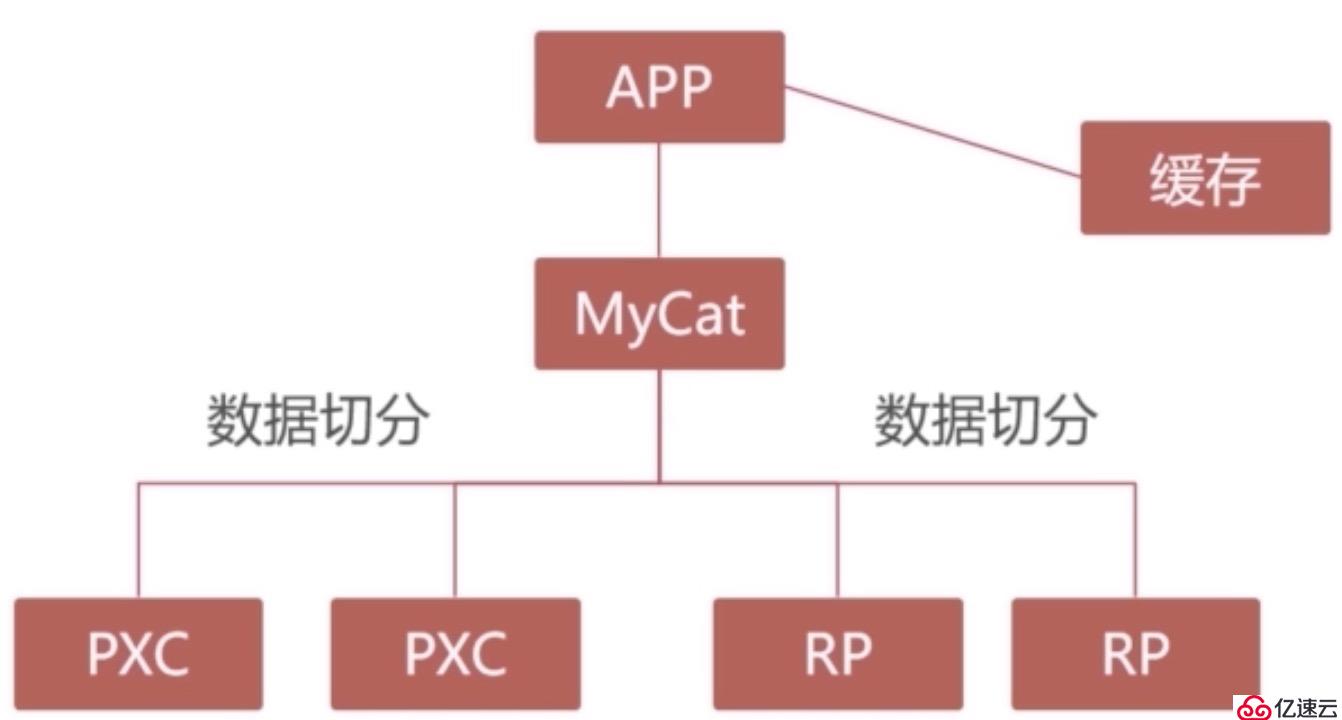
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





