溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了Python如何快速處理PDF表格數據,內容清晰明了,對此有興趣的小伙伴可以學習一下,相信大家閱讀完之后會有幫助。
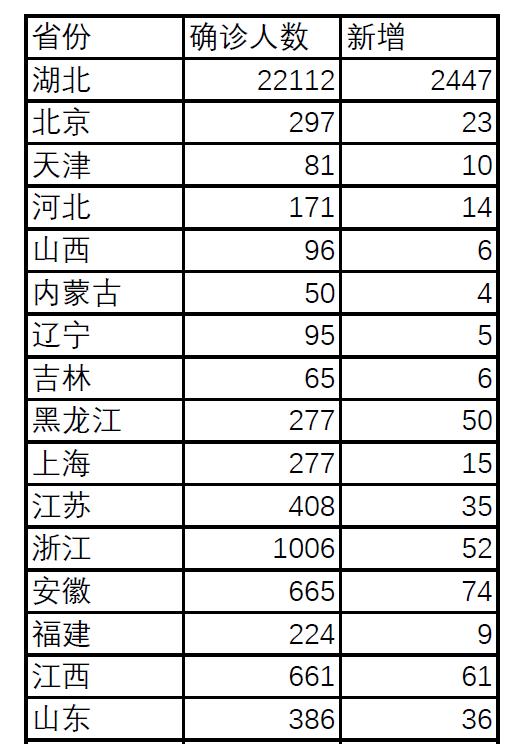
我們有下面一張PDF格式存儲的表格,現在需要使用Python將它提取出來。
使用Python提取表格數據需要使用pdfplumber模塊,打開CMD,安裝代碼如下:
pip install pdfplumber
安裝完之后,將需要使用的模塊導入
import pdfplumberimport pandas as pd
然后打開PDF文件
# 使用with語句打開pdf文件
with pdfplumber.open("D:\\python\\cai\\yq.pdf") as pdf:
# pages[0]表示取第1頁
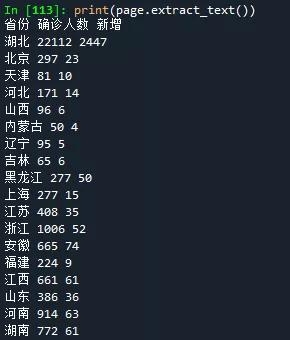
page = pdf.pages[0]我們來打印輸出下獲取到的文本,這句語句只是幫我們驗證下是否成功獲取到PDF里的內容
print(page.extract_text())
執行的結果如下,看來是成功了
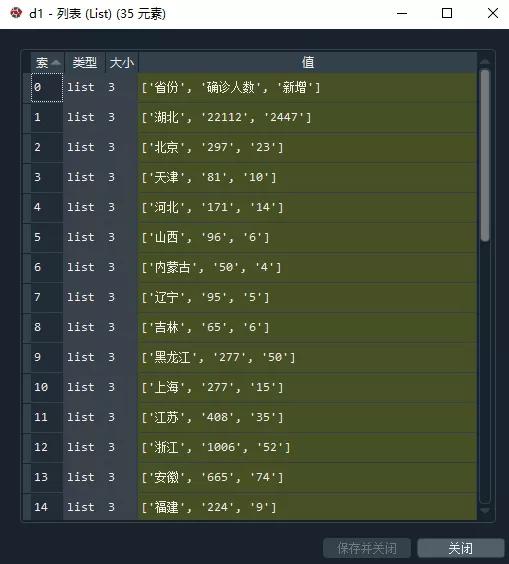
然后可以使用extract_table()函數獲取表格,如果有多個表格,可以使用extract_tables()函數,就是多了個s
d1=page.extract_table()
執行代碼后,將得到一個列表,還不是數據框
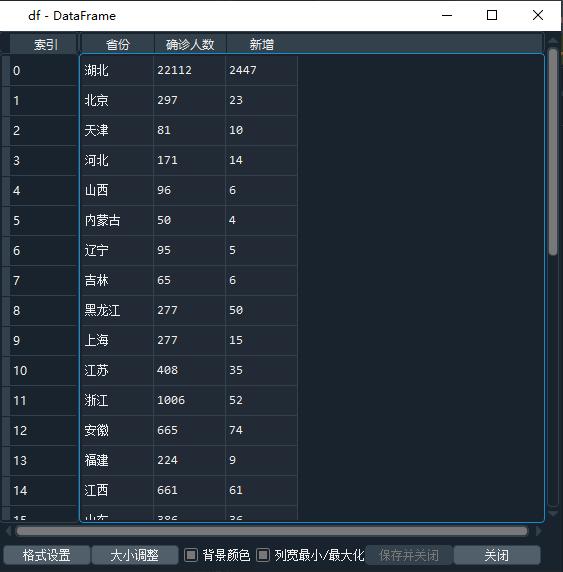
所以最后一步就是將列表轉為數據框就可以了,代碼如下:
df = pd.DataFrame(d1[1:], columns=d1[0])
執行代碼后,將得到了df數據框
有幾個注意事項要提醒下:
1.pdf表格中的數據,對于同一個數據或內容,不要有換行,如果換行,可能被識別為2個數據;
2.pdf中的表格一定要有邊框,沒有邊框的話,否則使用extract_table()函數就無法獲取表格數據,extract_text()還是可以獲取文本信息的,不要問我是怎么知道的,說多了都是淚。
我們現在有一份PDF數據,里面有三頁,每頁都有一樣數據結構但數據不同的數據表,現在需要使用Python將它批量提取出來。
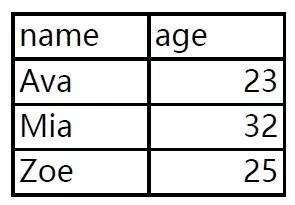
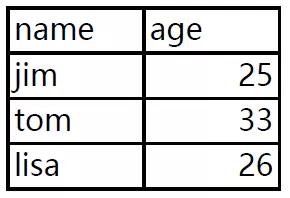
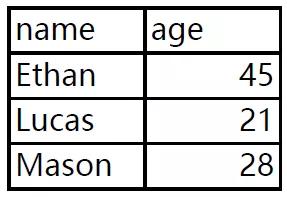
有了上回經驗,我們就直接上代碼:
import pdfplumber
import pandas as pd
# 創建一個空數據框
df = pd.DataFrame()
# 使用with語句打開pdf文件
with pdfplumber.open("D:\\python\\cai\\5.pdf") as pdf:
# 使用for循環遍歷每個pages
for page in pdf.pages:
# 取出當前頁表格,結果為列表
d=page.extract_table()
# 將列表轉為數據框
df1 = pd.DataFrame(d[1:], columns=d[0])
#添加至df數據框中
df = df.append(df1)執行代碼后,將得到了df數據框

是不是so easy 呢?
看完上述內容,是不是對Python如何快速處理PDF表格數據有進一步的了解,如果還想學習更多內容,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





