溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編這次要給大家分享的是淺談Tensorflow中k.gradients()和tf.stop_gradient(),文章內容豐富,感興趣的小伙伴可以來了解一下,希望大家閱讀完這篇文章之后能夠有所收獲。
上周在實驗室開荒某個代碼,看到中間這么一段,對Tensorflow中的stop_gradient()還不熟悉,特此周末進行重新并總結。
y = xx + K.stop_gradient(rounded - xx)
這代碼最終調用位置在tensoflow.python.ops.gen_array_ops.stop_gradient(input, name=None),關于這段代碼為什么這樣寫的意義在文末給出。
【stop_gradient()意義】
用stop_gradient生成損失函數w.r.t.的梯度。
【tf.gradients()理解】
tf中我們只需要設計我們自己的函數,tf提供提供強大的自動計算函數梯度方法,tf.gradients()。
tf.gradients( ys, xs, grad_ys=None, name='gradients', colocate_gradients_with_ops=False, gate_gradients=False, aggregation_method=None, stop_gradients=None, unconnected_gradients=tf.UnconnectedGradients.NONE )
gradients() adds ops to the graph to output the derivatives of ys with respect to xs. It returns a list of Tensor of length len(xs) where each tensor is the sum(dy/dx) for y in ys.
1、tf.gradients()實現ys對xs的求導
2、ys和xs可以是Tensor或者list包含的Tensor
3、求導返回值是一個list,list的長度等于len(xs)
eg.假設返回值是[grad1, grad2, grad3],ys=[y1, y2],xs=[x1, x2, x3]。則計算過程為:
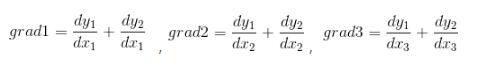
import numpy as np
import tensorflow as tf
#構造數據集
x_pure = np.random.randint(-10, 100, 32)
x_train = x_pure + np.random.randn(32) / 32
y_train = 3 * x_pure + 2 + np.random.randn(32) / 32
x_input = tf.placeholder(tf.float32, name='x_input')
y_input = tf.placeholder(tf.float32, name='y_input')
w = tf.Variable(2.0, name='weight')
b = tf.Variable(1.0, name='biases')
y = tf.add(tf.multiply(x_input, w), b)
loss_op = tf.reduce_sum(tf.pow(y_input - y, 2)) / (2 * 32)
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss_op)
gradients_node = tf.gradients(loss_op, w)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
for i in range(20):
_, gradients, loss = sess.run([train_op, gradients_node, loss_op], feed_dict={x_input: x_train[i], y_input: y_train[i]})
print("epoch: {} \t loss: {} \t gradients: {}".format(i, loss, gradients))
sess.close()自定義梯度和更新函數
import numpy as np
import tensorflow as tf
#構造數據集
x_pure = np.random.randint(-10, 100, 32)
x_train = x_pure + np.random.randn(32) / 32
y_train = 3 * x_pure + 2 + np.random.randn(32) / 32
x_input = tf.placeholder(tf.float32, name='x_input')
y_input = tf.placeholder(tf.float32, name='y_input')
w = tf.Variable(2.0, name='weight')
b = tf.Variable(1.0, name='biases')
y = tf.add(tf.multiply(x_input, w), b)
loss_op = tf.reduce_sum(tf.pow(y_input - y, 2)) / (2 * 32)
# train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss_op)
#自定義權重更新
grad_w, grad_b = tf.gradients(loss_op, [w, b])
new_w = w.assign(w - 0.01 * grad_w)
new_b = b.assign(b - 0.01 * grad_b)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
for i in range(20):
_, gradients, loss = sess.run([new_w, new_b, loss_op], feed_dict={x_input: x_train[i], y_input: y_train[i]})
print("epoch: {} \t loss: {} \t gradients: {}".format(i, loss, gradients))
sess.close()【tf.stop_gradient()理解】
在tf.gradients()參數中存在stop_gradients,這是一個List,list中的元素是tensorflow graph中的op,一旦進入這個list,將不會被計算梯度,更重要的是,在該op之后的BP計算都不會運行。
import numpy as np import tensorflow as tf a = tf.constant(0.) b = 2 * a c = a + b g = tf.gradients(c, [a, b]) with tf.Session() as sess: tf.global_variables_initializer().run() print(sess.run(g)) #輸出[3.0, 1.0]
在用一個stop_gradient()的例子
import tensorflow as tf #實驗一 w1 = tf.Variable(2.0) w2 = tf.Variable(2.0) a = tf.multiply(w1, 3.0) a_stoped = tf.stop_gradient(a) # b=w1*3.0*w2 b = tf.multiply(a_stoped, w2) gradients = tf.gradients(b, xs=[w1, w2]) print(gradients) #輸出[None, <tf.Tensor 'gradients/Mul_1_grad/Reshape_1:0' shape=() dtype=float32>] #實驗二 a = tf.Variable(1.0) b = tf.Variable(1.0) c = tf.add(a, b) c_stoped = tf.stop_gradient(c) d = tf.add(a, b) e = tf.add(c_stoped, d) gradients = tf.gradients(e, xs=[a, b]) with tf.Session() as sess: tf.global_variables_initializer().run() print(sess.run(gradients)) #因為梯度從另外地方傳回,所以輸出 [1.0, 1.0]
【答案】
開始提出的問題,為什么存在那段代碼:
t = g(x)
y = t + tf.stop_gradient(f(x) - t)
這里,我們本來的前向傳遞函數是XX,但是想要在反向時傳遞的函數是g(x),因為在前向過程中,tf.stop_gradient()不起作用,因此+t和-t抵消掉了,只剩下f(x)前向傳遞;而在反向過程中,因為tf.stop_gradient()的作用,使得f(x)-t的梯度變為了0,從而只剩下g(x)在反向傳遞。
看完這篇關于淺談Tensorflow中k.gradients()和tf.stop_gradient()的文章,如果覺得文章內容寫得不錯的話,可以把它分享出去給更多人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





