溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下關于Keras中categorical_crossentropy函數的詳細用法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討方法吧!
from keras.utils.np_utils import to_categorical
注意:當使用categorical_crossentropy損失函數時,你的標簽應為多類模式,例如如果你有10個類別,每一個樣本的標簽應該是一個10維的向量,該向量在對應有值的索引位置為1其余為0。
可以使用這個方法進行轉換:
from keras.utils.np_utils import to_categorical
categorical_labels = to_categorical(int_labels, num_classes=None)
以mnist數據集為例:
from keras.datasets import mnist (X_train, y_train), (X_test, y_test) = mnist.load_data() y_train = to_categorical(y_train, 10) y_test = to_categorical(y_test, 10) ... model.compile(loss='categorical_crossentropy', optimizer='adam') model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=2)
補充知識:Keras中損失函數binary_crossentropy和categorical_crossentropy產生不同結果的分析
問題
在使用keras做對心電信號分類的項目中發現一個問題,這個問題起源于我的一個使用錯誤:
binary_crossentropy 二進制交叉熵用于二分類問題中,categorical_crossentropy分類交叉熵適用于多分類問題中,我的心電分類是一個多分類問題,但是我起初使用了二進制交叉熵,代碼如下所示:
sgd = SGD(lr=0.003, decay=0, momentum=0.7, nesterov=False) model.compile(loss='categorical_crossentropy', optimizer='sgd',metrics=['accuracy']) model.fit(X_train, Y_train, validation_data=(X_test,Y_test),batch_size=16, epochs=20) score = model.evaluate(X_test, Y_test, batch_size=16)
注意:我的CNN網絡模型在最后輸入層正確使用了應該用于多分類問題的softmax激活函數
后來我在另一個殘差網絡模型中對同類數據進行相同的分類問題中,正確使用了分類交叉熵,令人奇怪的是殘差模型的效果遠弱于普通卷積神經網絡,這一點是不符合常理的,經過多次修改分析終于發現可能是損失函數的問題,因此我使用二進制交叉熵在殘差網絡中,終于取得了優于普通卷積神經網絡的效果。
因此可以斷定問題就出在所使用的損失函數身上
原理
本人也只是個只會使用框架的調參俠,對于一些原理也是一知半解,經過了學習才大致明白,將一些原理記錄如下:
要搞明白分類熵和二進制交叉熵先要從二者適用的激活函數說起
激活函數
sigmoid, softmax主要用于神經網絡輸出層的輸出。
softmax函數
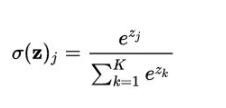
softmax可以看作是Sigmoid的一般情況,用于多分類問題。
Softmax函數將K維的實數向量壓縮(映射)成另一個K維的實數向量,其中向量中的每個元素取值都介于 (0,1) 之間。常用于多分類問題。
sigmoid函數
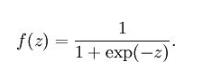
Sigmoid 將一個實數映射到 (0,1) 的區間,可以用來做二分類。Sigmoid 在特征相差比較復雜或是相差不是特別大時效果比較好。Sigmoid不適合用在神經網絡的中間層,因為對于深層網絡,sigmoid 函數反向傳播時,很容易就會出現梯度消失的情況(在 sigmoid 接近飽和區時,變換太緩慢,導數趨于 0,這種情況會造成信息丟失),從而無法完成深層網絡的訓練。所以Sigmoid主要用于對神經網絡輸出層的激活。
分析
所以說多分類問題是要softmax激活函數配合分類交叉熵函數使用,而二分類問題要使用sigmoid激活函數配合二進制交叉熵函數適用,但是如果在多分類問題中使用了二進制交叉熵函數最后的模型分類效果會虛高,即比模型本身真實的分類效果好。
所以就會出現我遇到的情況,這里引用了論壇一位大佬的樣例:
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # WRONG way model.fit(x_train, y_train, batch_size=batch_size, epochs=2, # only 2 epochs, for demonstration purposes verbose=1, validation_data=(x_test, y_test)) # Keras reported accuracy: score = model.evaluate(x_test, y_test, verbose=0) score[1] # 0.9975801164627075 # Actual accuracy calculated manually: import numpy as np y_pred = model.predict(x_test) acc = sum([np.argmax(y_test[i])==np.argmax(y_pred[i]) for i in range(10000)])/10000 acc # 0.98780000000000001 score[1]==acc # False
樣例中模型在評估中得到的準確度高于實際測算得到的準確度,網上給出的原因是Keras沒有定義一個準確的度量,但有幾個不同的,比如binary_accuracy和categorical_accuracy,當你使用binary_crossentropy時keras默認在評估過程中使用了binary_accuracy,但是針對你的分類要求,應當采用的是categorical_accuracy,所以就造成了這個問題(其中的具體原理我也沒去看源碼詳細了解)
解決
所以問題最后的解決方法就是:
對于多分類問題,要么采用
from keras.metrics import categorical_accuracy model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[categorical_accuracy])
要么采用
model.compile(loss='categorical_crossentropy',
optimizer='adam',metrics=['accuracy'])
看完了這篇文章,相信你對關于Keras中categorical_crossentropy函數的詳細用法有了一定的了解,想了解更多相關知識,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





