溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編這次要給大家分享的是Redis Cluster集群數據分片機制是什么,文章內容豐富,感興趣的小伙伴可以來了解一下,希望大家閱讀完這篇文章之后能夠有所收獲。
Redis Cluster數據分片機制
Redis 集群簡介
Redis Cluster 是 Redis 的分布式解決方案,在 3.0 版本正式推出,有效地解決了 Redis 分布式方面的需求。
Redis Cluster 一般由多個節點組成,節點數量至少為 6 個才能保證組成完整高可用的集群,其中三個為主節點,三個為從節點。三個主節點會分配槽,處理客戶端的命令請求,而從節點可用在主節點故障后,頂替主節點。
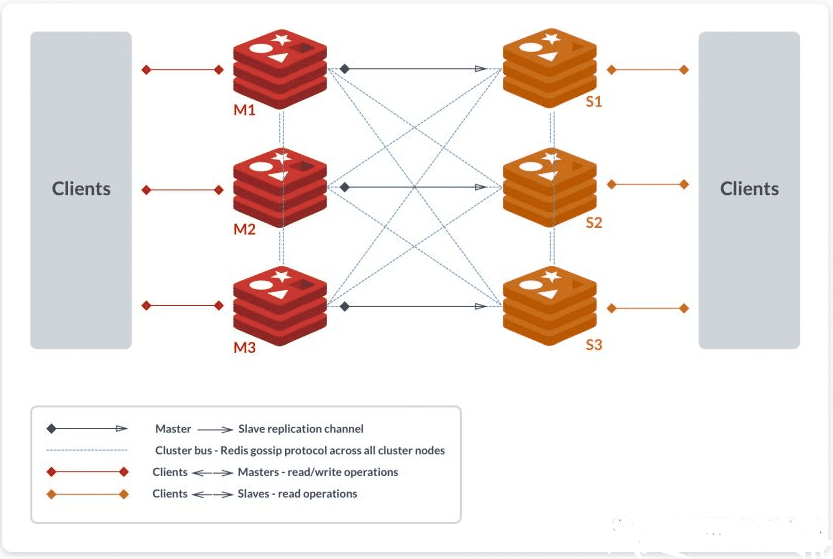
如上圖所示,該集群中包含 6 個 Redis 節點,3主3從,分別為M1,M2,M3,S1,S2,S3。除了主從 Redis 節點之間進行數據復制外,所有 Redis 節點之間采用 Gossip 協議進行通信,交換維護節點元數據信息。
一般來說,主 Redis 節點會處理 Clients 的讀寫操作,而從節點只處理讀操作。
數據分片策略
分布式數據存儲方案中最為重要的一點就是數據分片,也就是所謂的 Sharding。
為了使得集群能夠水平擴展,首要解決的問題就是如何將整個數據集按照一定的規則分配到多個節點上,常用的數據分片的方法有:范圍分片,哈希分片,一致性哈希算法和虛擬哈希槽等。
范圍分片假設數據集是有序,將順序相臨近的數據放在一起,可以很好的支持遍歷操作。范圍分片的缺點是面對順序寫時,會存在熱點。比如日志類型的寫入,一般日志的順序都是和時間相關的,時間是單調遞增的,因此寫入的熱點永遠在最后一個分片。
對于關系型的數據庫,因為經常性的需要表掃描或者索引掃描,基本上都會使用范圍的分片策略。
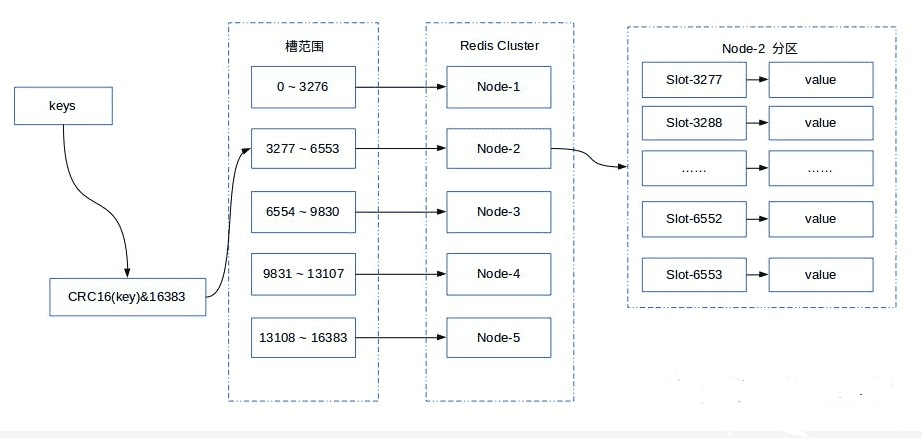
Redis Cluster 采用虛擬哈希槽分區,所有的鍵根據哈希函數映射到 0 ~ 16383 整數槽內,計算公式:slot = CRC16(key) & 16383。每一個節點負責維護一部分槽以及槽所映射的鍵值數據。
Redis 虛擬槽分區的特點:
解耦數據和節點之間的關系,簡化了節點擴容和收縮難度。節點自身維護槽的映射關系,不需要客戶端或者代理服務維護槽分區元數據支持節點、槽和鍵之間的映射查詢,用于數據路由,在線集群伸縮等場景。
Redis 集群提供了靈活的節點擴容和收縮方案。在不影響集群對外服務的情況下,可以為集群添加節點進行擴容也可以下線部分節點進行縮容。可以說,槽是 Redis 集群管理數據的基本單位,集群伸縮就是槽和數據在節點之間的移動。
下面我們就先來看一下 Redis 集群伸縮的原理。然后再了解當 Redis 節點數據遷移過程中或者故障恢復時如何保證集群可用。
擴容集群
為了讓讀者更好的理解上線節點時的擴容操作,我們通過 Redis Cluster 的命令來模擬整個過程。
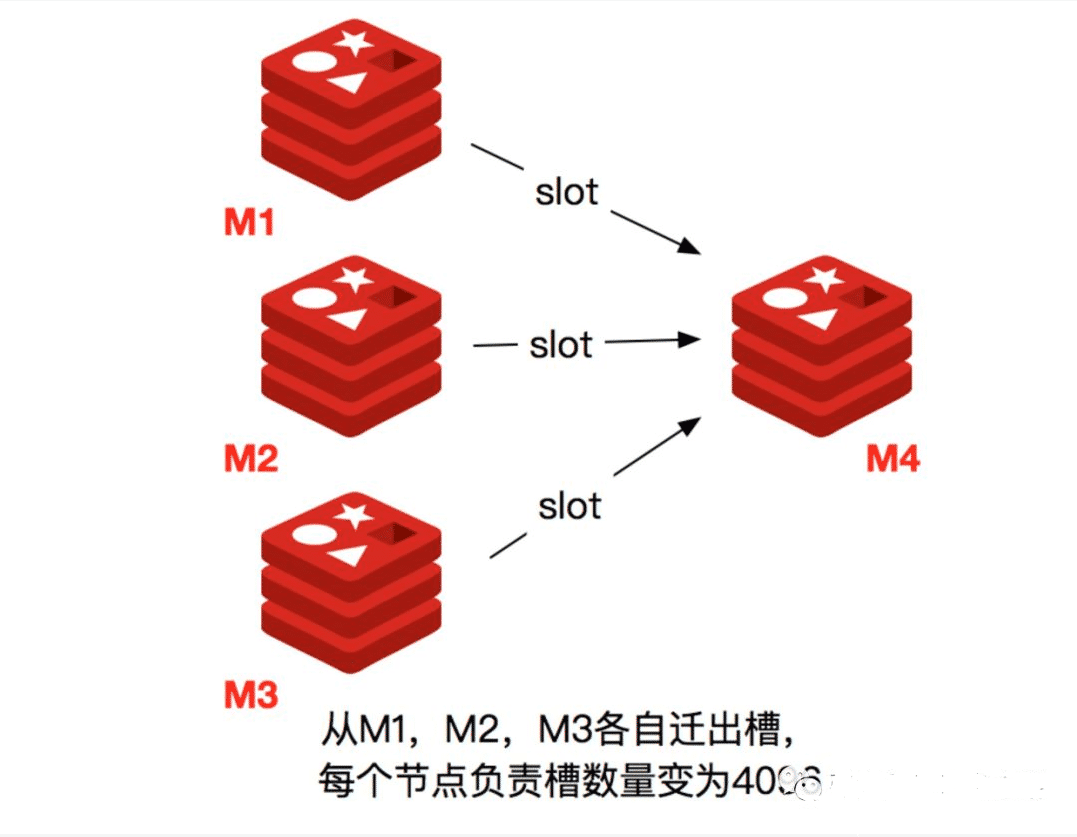
當一個 Redis 新節點運行并加入現有集群后,我們需要為其遷移槽和數據。首先要為新節點指定槽的遷移計劃,確保遷移后每個節點負責相似數量的槽,從而保證這些節點的數據均勻。
1) 首先啟動一個 Redis 節點,記為 M4。
2) 使用 cluster meet 命令,讓新 Redis 節點加入到集群中。新節點剛開始都是主節點狀態,由于沒有負責的>槽,所以不能接受任何讀寫操作,后續我們就給他遷移槽和填充數據。
3) 對 M4 節點發送 cluster setslot { slot } importing { sourceNodeId } 命令,讓目標節點準備導入槽的數據。
4) 對源節點,也就是 M1,M2,M3 節點發送 cluster setslot { slot } migrating { targetNodeId } 命令,讓源節>點準備遷出槽的數據。
5) 源節點執行 cluster getkeysinslot { slot } { count } 命令,獲取 count 個屬于槽 { slot } 的鍵,然后執行步驟>六的操作進行遷移鍵值數據。
6) 在源節點上執行 migrate { targetNodeIp} " " 0 { timeout } keys { key... } 命令,把獲取的鍵通過 pipeline 機制>批量遷移到目標節點,批量遷移版本的 migrate 命令在 Redis 3.0.6 以上版本提供。
7) 重復執行步驟 5 和步驟 6 直到槽下所有的鍵值數據遷移到目標節點。
8) 向集群內所有主節點發送 cluster setslot { slot } node { targetNodeId } 命令,通知槽分配給目標節點。為了>保證槽節點映射變更及時傳播,需要遍歷發送給所有主節點更新被遷移的槽執行新節點。
收縮集群
收縮節點就是將 Redis 節點下線,整個流程需要如下操作流程。
1) 首先需要確認下線節點是否有負責的槽,如果是,需要把槽遷移到其他節點,保證節點下線后整個集群槽節點映射的完整性。
2) 當下線節點不再負責槽或者本身是從節點時,就可以通知集群內其他節點忘記下線節點,當所有的節點忘記改節點后可以正常關閉。
下線節點需要將節點自己負責的槽遷移到其他節點,原理與之前節點擴容的遷移槽過程一致。
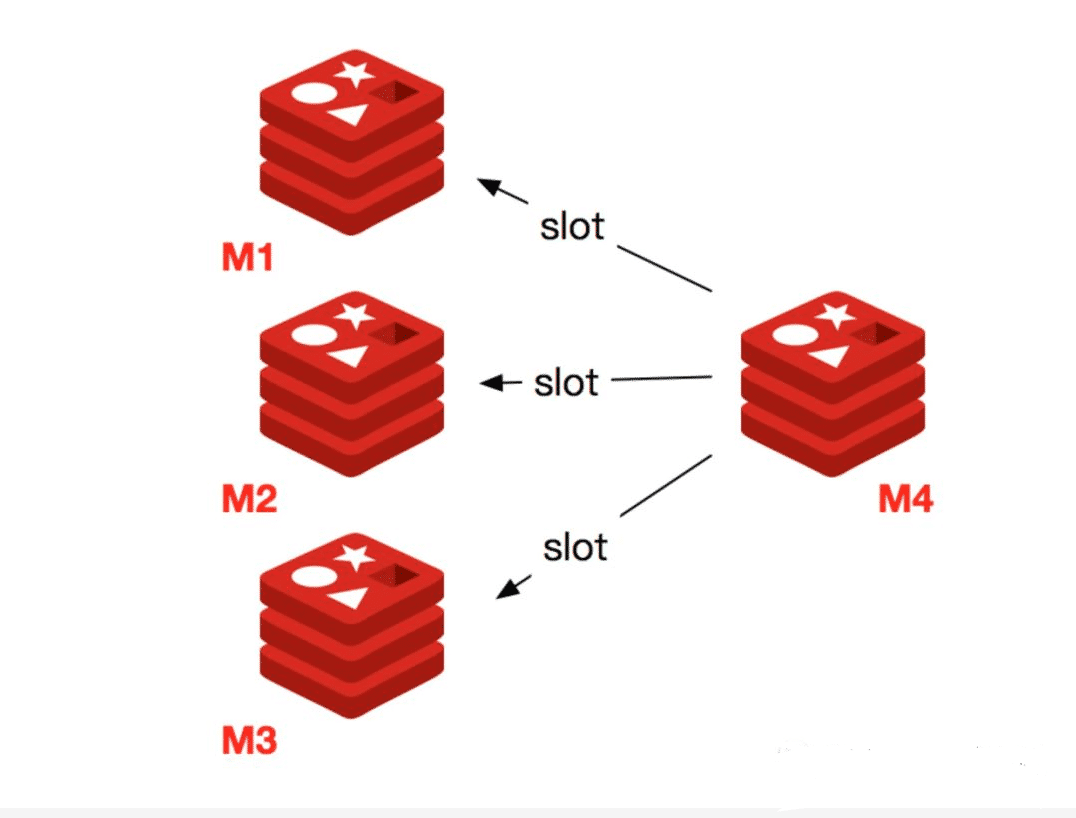
遷移完槽后,還需要通知集群內所有節點忘記下線的節點,也就是說讓其他節點不再與要下線的節點進行 Gossip 消息交換。
Redis 集群使用 cluster forget { downNodeId } 命令來講指定的節點加入到禁用列表中,在禁用列表內的節點不再發送 Gossip 消息。
客戶端路由
在集群模式下,Redis 節點接收任何鍵相關命令時首先計算鍵對應的槽,在根據槽找出所對應的節點,如果節點是自身,則處理鍵命令;否則回復 MOVED 重定向錯誤,通知客戶端請求正確的節點。這個過程稱為 MOVED 重定向。
需要注意的是 Redis 計算槽時并非只簡單的計算鍵值內容,當鍵值內容包括大括號時,則只計算括號內的內容。比如說,key 為 user:{10000}:books時,計算哈希值只計算10000。
MOVED 錯誤示例顯示的信息如下,鍵 x 所屬的哈希槽 3999 ,以及負責處理這個槽的節點的 IP 和端口號 127.0.0.1:6381 。 客戶端需要根據這個 IP 和端口號, 向所屬的節點重新發送一次 GET 命令請求。
<codeclass="hljs"></code>
由于請求重定向會增加 IO 開銷,這不是 Redis 集群高效的使用方式,而是要使用 Smart 集群客戶端。Smart 客戶端通過在內部維護 slot 到 Redis 節點的映射關系,本地就可以實現鍵到節點的查找,從而保證 IO 效率的最大化,而 MOVED 重定向負責協助客戶端更新映射關系。
Redis 集群支持在線遷移槽( slot ) 和數據來完成水平伸縮,當 slot 對應的數據從源節點到目標節點遷移過程中,客戶端需要做到智能遷移,保證鍵命令可正常執行。例如當 slot 數據從源節點遷移到目標節點時,期間可能出現一部分數據在源節點,而另一部分在目標節點。
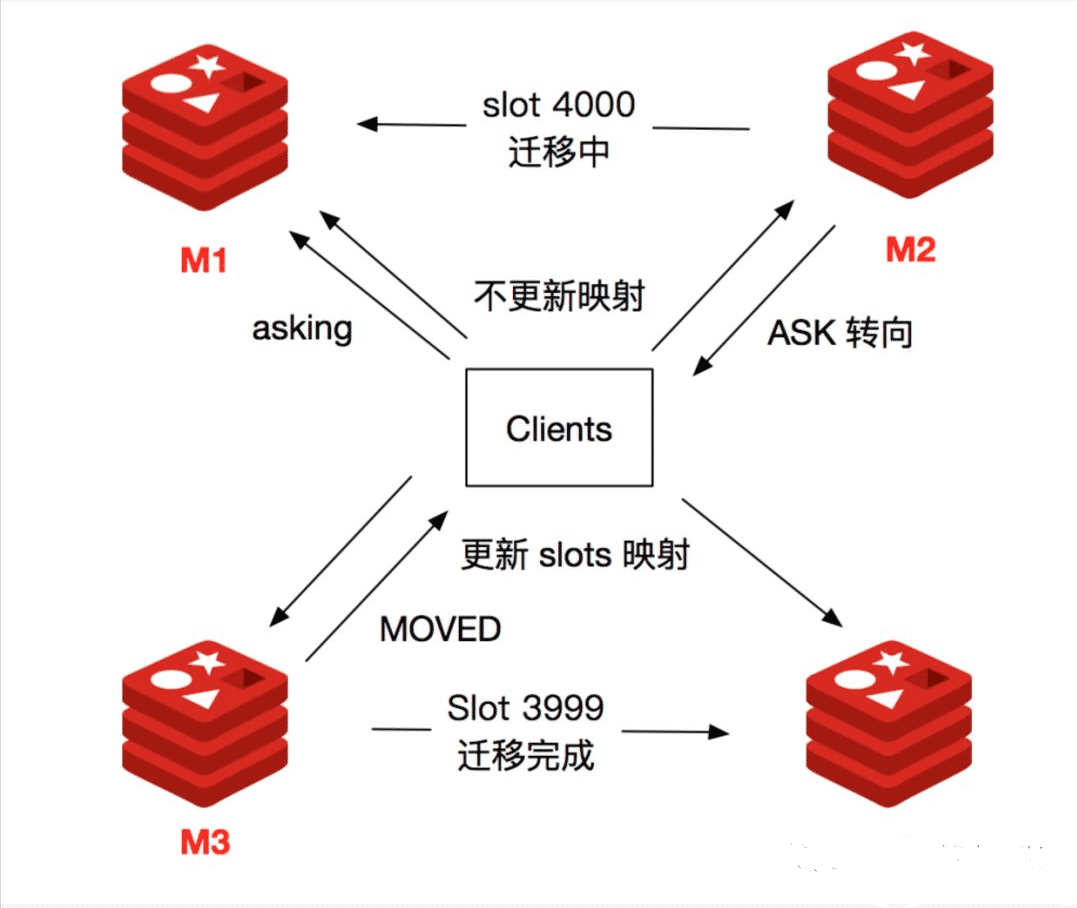
所以,綜合上述情況,客戶端命令執行流程如下所示:
客戶端從 ASK 重定向異常提取出目標節點信息,發送 asking 命令到目標節點打開客戶端連接標識,再執行鍵命令。
ASK 和 MOVED 雖然都是對客戶端的重定向控制,但是有著本質區別。ASK 重定向說明集群正在進行 slot 數據遷移,客戶端無法知道什么時候遷移完成,因此只能是臨時性的重定向,客戶端不會更新 slot 到 Redis 節點的映射緩存。但是 MOVED 重定向說明鍵對應的槽已經明確指定到新的節點,因此需要更新 slot 到 Redis 節點的映射緩存。
故障轉移
當 Redis 集群內少量節點出現故障時通過自動故障轉移保證集群可以正常對外提供服務。
當某一個 Redis 節點客觀下線時,Redis 集群會從其從節點中通過選主選出一個替代它,從而保證集群的高可用性。這塊內容并不是本文的核心內容,感興趣的同學可以自己學習。
但是,有一點要注意。默認情況下,當集群 16384 個槽任何一個沒有指派到節點時整個集群不可用。執行任何鍵命令返回 CLUSTERDOWN Hash slot not served 命令。當持有槽的主節點下線時,從故障發現到自動完成轉移期間整個集群是不可用狀態,對于大多數業務無法忍受這情況,因此建議將參數 cluster-require-full-coverage 配置為 no ,當主節點故障時只影響它負責槽的相關命令執行,不會影響其他主節點的可用性。
看完這篇關于Redis Cluster集群數據分片機制是什么的文章,如果覺得文章內容寫得不錯的話,可以把它分享出去給更多人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





