溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
數據科學異常值檢測原理是什么?異常值的檢測方法有基于統計的方法,基于聚類的方法,以及一些專門檢測異常值的方法等。使用pandas,可以直接使用describe()來觀察數據的統計性描述,或者簡單使用散點圖也能很清晰的觀察到異常值的存在。一起跟小編來看看吧!

一、數據科學異常值檢測前提
數據樣本符合標準正態分布,正態分布的核心是中心極限定理即:如果一個事物受到多種因素的影響,不管每個因素本身是什么分布,它們加總后,結果的平均值就是正態分布。如果要符合正態分布則這些因素必須彼此獨立,彼此不獨立的各項因素會互相加強影響,那么就構不成正態分布。
二、數據科學異常值檢測原理
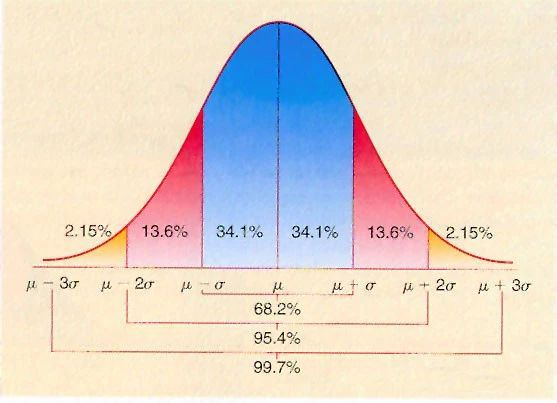
標準正態分布下的曲線為鐘型曲線,期望值μ決定了其位置,其標準差σ決定了分布的幅度。當μ = 0,σ = 1時的正態分布是標準正態分布。因此對于一組數據,如果符合正態分布,則可以通過經驗法則來檢測異常值,同圖中可以發現,68.2%的測量值落在μ值處正負一個標準差σ的區間內,95.4%的測量值將落在μ值處正負兩個標準差σ的區間內,99.7%的值落在μ值處正負三個標準差σ的區間內。因此,對于一組符合正態分布的數據,如果某個值距離μ值超過三個標準差σ則可以判斷這個值屬于異常數據。
三、計算步驟
μ值:μ是遵從正態分布的隨機變量的均值,由于前提是各種因素對結果的影響為相加,因此μ值的計算可以為樣本數據的算術平均值。
標準差σ:所有數據減去其平均值的平方和,所得結果除以該組數之個數N(數據集為總體數據情況,一般用于大數據算法)或者個數N減1(數據集為樣本數據情況,認為數據集不是總體數據而是總體數據的一部分,一般用于統計學),再把所得值開根號,所得之數就是這組數據的標準差。
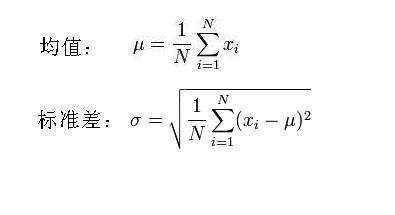
判斷邏輯:計算μ+3σ,μ-3σ,當單個數據大于μ+3σ或者小于μ-3σ時,認為此數據為異常值,因為按照經驗法則,此數據在數據集的99.7%范圍外。
首先理解數據科學異常值檢測原理,掌握計算步驟,最終實現對數據科學異常值檢測。
以上就是數據科學異常值檢測原理是什么的詳細內容了,看完之后是否有所收獲呢?如果如果想了解更多,歡迎來億速云行業資訊!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





