溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
組名稱和組數量已知的分組匯總被稱為固定分組匯總,此類算法的分組依據來自于數據集之外,比如:按照參數列表中的客戶名單分組,或按照條件列表進行分組。此類算法會涉及分組依據是否超出數據集、是否需要多余的組、數據是否重疊等問題,解決起來有一定的難度。本文將介紹R語言實現固定分組匯總的方法。
例1:分組依據不超出數據集
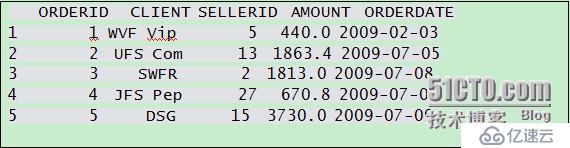
數據框sales是訂單記錄,其中CLIENT列是客戶名,AMOUNT列是訂單金額,請將sales按照“潛力客戶列表”進行分組,并對各組的AMOUNT列匯總求和。潛力客戶列表為[ARO,BON,CHO],該列表恰好是CLIENT列的子集。
說明:sales的來源可以是數據庫也可以是文件,比如:orders<-read.table("sales.txt",sep="\t", header=TRUE)。其前幾行數據如下:
代碼:
byFac<-factor(sales$CLIENT,levels=c("ARO","BON","CHO"))
result<-aggregate(sales$AMOUNT,list(byFac),sum)
計算結果:

代碼解讀:
1.函數factor生成了一個分組依據(在R中被稱為因子),函數aggregate按照分組依據進行分組匯總,整段代碼的結構非常清晰。
2.需要注意的是,分組依據不是向量或數組,因此不能直接寫成byFac<- c("ARO","BON","CHO")。分組依據也不能直接使用,還需要轉化成list類型。這些方面是初學者不易理解的地方,尤應注意。
3.如果以CLIENT列為分組依據(即非固定分組),則只需一句代碼就能實現:
result<-aggregate(sales$AMOUNT,list(sales$CLIENT),sum)
總結:使用aggregate可以輕松實現本案例。
例2:分組依據超出數據集
分組依據僅限于列數據,這屬于特殊情況,實際上由于分組依據來自于數據集之外(比如外部參數),它的成員很可能不在列數據中。本案例試圖解決這樣的問題。
假設“潛力客戶列表”的值為[ARO,BON,CHO,ZTOZ],請將sales按照“潛力客戶列表”將數據分為四組,并對各組的AMOUNT列匯總求和。注意,客戶ZTOZ不在CLIENT列中。
與例1類似的代碼:
byFac<-factor(sales$CLIENT,levels=c("ARO","BON","CHO","ZTOZ"))
result<-aggregate(sales$AMOUNT,list(byFac),sum)
上述代碼的計算結果是:

可以看到,計算結果中只有三組數據,缺失了ZTOZ,而不是要求中的四組。顯然,上述代碼不能實現本案例,需要改進。
改進后的代碼:
byFac<-factor(sales$CLIENT,levels=c("ARO","BON","CHO","ZTOZ"))
tapply(sales$AMOUNT, list(byFac),function(x) sum(x))
計算結果:

代碼解讀:
1.改進后的代碼更符合業務邏輯,四個分組都能呈現在結果中。
2.代碼中使用了tapply進行分組匯總,這個函數的通用性比aggregate好,但tapply的名字不如aggregate直觀,初學者大多搞不清楚。
3.ZTOZ的匯總值是NA,這說明ZTOZ不在CLIENT列中。如果ZTOZ的匯總值為0,則說明ZTOZ在CLIENT列中,但訂單金額為0。
4.本案例中,分組匯總的結果只有四組,多余的客戶不應該出現,這些客戶可以稱為“多余組”。計算多余組的匯總值不能在當前算法上簡單改造,需要使用新的函數:
filtered<-sales[!is.element(sales$CLIENT,byFac),]
redundant<-sum(filtered$AMOUNT)
這段代碼并不復雜,但實現思路和之前的代碼明顯不同。
總結:使用tapply可以輕松實現本案例。
例3:分組條件不重疊
以條件作為分組依據,這也是固定分組的一種,比如:將訂單金額按照1000、2000、4000劃分為四個區間,每個區間一組訂單,統計各組訂單的金額。
代碼
byFac<-cut(sales$AMOUNT,breaks=c(0,1000,2000,4000,Inf))
result<-tapply(sales$AMOUNT, list(byFac),function(x) sum(x))
計算結果:

代碼解讀:函數cut將數據框劃分為四個區間,函數tapply將數據框按照區間分組,并匯總出各組結果。
總結:cut和tapply配合可以輕松實現最簡單的條件分組。
例4:分組條件有重疊,重復計算結果
在最簡單的條件分組中,條件沒有發生重疊,但實際上發生重疊的情況很常見,比如將訂單金額按照如下規則分組:
1000至4000:常規訂單r14
2000以下:非重點訂單r2
3000以上:重點訂單r3
這里的常規訂單就會和另外兩組發生重疊。發生重疊時就有是否要把重疊的數據重復計算的問題,本案例先解決重復計算的情況。
代碼:
r14<-subset(sales,AMOUNT>=1000 & AMOUNT<=4000 )
r2<-subset(sales,AMOUNT<2000)
r3<-subset(sales,AMOUNT>3000 )
grouped<-list(r14=r14,r2=r2,r3=r3)
result<-lapply(grouped,FUN=function(x) sum(x$AMOUNT))
計算結果:

說明:r2和r3包含了r14的部分數據。
代碼解讀:
1.上述代碼可以解決本案例,但已經顯得很麻煩了,如果條件更多更復雜,上面的代碼將會更長。
2.這里用到了一個新的函數lapply。迄今為止,為了實現固定分組,我們已經使用了很多函數,包括:factor、aggregate、list、tapply、cut、subset、lapply等等。而且同為條件分組,僅僅因為條件是否重疊,我們就需要用不同的函數和不同的思路去實現,掌握這些用法還是相當困難的。
3.上述代碼的計算結果是list,前面幾個案例有的是data.frame,有的則是array,這些不一致的地方在實際使用中也會造成麻煩。
總結:可以實現本案例,但代碼較復雜,需要掌握很多函數。
例5:分組條件有重疊,結果不重復
之前的案例解決了數據重復時的問題,但有時我們需要不重復的計算結果,即:前面分組中出現過的數據不能出現在后面,針對本案例,具體的算法就是:r2不應該包含r14中的數據,r3不應當包含r2和r14中的數據。
代碼:
r14<-subset(sales,AMOUNT>=1000 & AMOUNT<=4000 )
r2<-subset(sales,AMOUNT<2000 & !(AMOUNT>=1000 & AMOUNT<=4000))
r3<-subset(sales,AMOUNT>3000 & !((AMOUNT>=1000 & AMOUNT<=4000)) & !(AMOUNT<2000))
grouped<-list(r14=r14,r2=r2,r3=r3)
result<-lapply(grouped,FUN=function(x) sum(x$AMOUNT))
計算結果

注意:不重復計算數據時,r2和r3的值比之前計算出的結果小。
代碼解讀:為了實現不重復計算,上述代碼加入了更多的邏輯判斷,這就使代碼復雜度進一步加大。可以想象,當分組數量較多,分組條件也比較復雜時,所要書寫的代碼量會相當大。
總結:可以實現本案例,但代碼復雜稍顯復雜。
第三方解決方案
上述例子也可以用Python、集算器、Perl等語言來實現。和R語言一樣,這幾種語言都可以實現固定分組匯總和結構化數據的計算,下面簡單介紹集算器的解決方案。
例1:
byFac=["ARO","BON","CHO"]
grouped=sales.align@a(byFac, CLIENT)
grouped.new(byFac(#), ~.sum(AMOUNT))
計算結果:

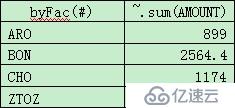
例2:
代碼和例1完全一樣,此處省略。
計算結果:
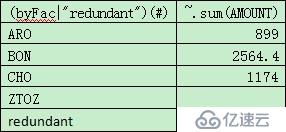
如果想統計多余組的匯總值,則代碼只需稍作改動:
byFac=["ARO","BON","CHO","ZTOZ"]
grouped=sales.align@a@n(byFac,CLIENT)
grouped.new((byFac|"redundant")(#), ~.sum(AMOUNT))
紅色部分即改動,其中@n表示在結果集中增加多余的一組,可以看到,這種寫法要比R的代碼易于掌握。
計算結果:
例3
對于簡單的條件分組,集算器只需將之前的align函數換為enum,其他地方不變。
byFac=["?<=1000" ,"?>1000 && ?<=2000","?>2000 && ?<=4000","?>4000"]
grouped=sales.enum(byFac,AMOUNT)
grouped.new(byFac(#),~.sum(AMOUNT))
計算結果:

集算器
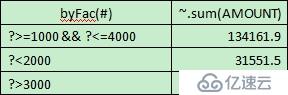
需要計算重復的數據時,只需要在之前的代碼中加入@r選項。
byFac=["?>=1000 && ?<=4000","?<2000" ,"?>3000"]
grouped=sales.enum@r(byFac,AMOUNT)
grouped.new(byFac(#),~.sum(AMOUNT))
計算結果:

集算器
不需要計算重復的數據時,去掉@r選項即可,和簡單條件分組完全一樣。
byFac=["?>=1000 && ?<=4000","?<2000" ,"?>3000"]
grouped=sales.enum(byFac,AMOUNT)
grouped.new(byFac(#),~.sum(AMOUNT))
計算結果:
可以看到,集算器只需要align和enum這兩個函數就可以實現所有類型的固定分組匯總,代碼結構一致,解決思路簡單。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





