溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關RSS與爬蟲怎么搜集數據的內容。小編覺得挺實用的,因此分享給大家做個參考。一起跟隨小編過來看看吧。
摘要:數據的價值被挖掘出來之前,先要通過收集、存儲、分析計算等過程,獲得全面、準確的數據是數據價值挖掘的基礎。本期CSDN云計算俱樂部“大數據故事”將從最為常見的數據搜集方式說起——RSS和搜索引擎爬蟲。
12月30日,CSDN云計算俱樂部活動在3W咖啡舉行,活動主題是“RSS與爬蟲:大數據的故事——從如何搜集數據開始”。數據的價值被挖掘出來之前,先要通過收集、存儲、分析計算等過程,獲得全面、準確的數據是數據價值挖掘的基礎。也許當下數據并不能為企業或組織帶來實際價值,但作為有遠見的決策者應該意識到,應盡早收集、保存重要數據,數據就是財富。本期“大數據故事”將從最為常見的數據搜集方式說起——RSS和搜索引擎爬蟲。

活動現場座無虛席
首先,北京萬方軟件股份有限公司圖書館事業部總經理崔克俊分享的主題是“大規模進行RSS聚合和網站下載在科學研究中的初步應用”。崔克俊在圖書館、情報行業從業12年,有豐富的數據采集經驗,他主要分享了信息聚合的一種重要方式RSS及其實現技術。
RSS(Really Simple Syndication)是一種消息來源格式規范,用以聚合經常發布更新數據的網站,例如博客文章、新聞、音頻或視頻的網摘。RSS文件包含了全文或是節錄的文字,再加上發用者所訂閱之網摘布數據和授權的元數據。
對某一行業密切相關的幾百個甚至幾千個RSS種子進行的聚合,將能快速、全面了解某一行的最新動態;對某一行業的的幾十個甚至幾百個網站進行完整的數據下載,并進行數據挖掘,將能了解某一主題在該行業發展的來龍去脈。

北京萬方軟件股份有限公司圖書館事業部總經理 崔克俊
崔克俊以高能物理研究所為例,介紹了RSS在科研院所的應用。 高能物理信息監測對象為全球高能物理同行機構:實驗室、行業學會、國際協會、各國主管科研政府機構、重點綜合性科學出版物、高能物理試驗項目和實驗設施。監控的信息類型為:新聞、論文、會議報告、分析評論、預印本、案例研究、多媒體、圖書、招聘信息等。
高能物理文獻信息所采用最先進的開源內容管理系統 Drupal,開源搜索技術 Apache Solr,以及Google員工開發的能實時訂閱新聞的 PubSubHubbub技術和Amazon的 OpenSearch,建立了一套高能物理信息監測系統,有別于傳統的RSS訂閱和推送,實現了幾乎實時的信息抓取和任意關鍵詞、任意類別、復合條件新聞的主動推送。
接下來,崔克俊分享了Drupal、Apache Solr、PubSubHubbub和OpenSearch等技術的使用心得。
接下來,宜搜科技搜索部架構師爬蟲組負責人葉順平帶來了題為“網頁搜索爬蟲時效性系統”的分享,包括時效性系統的主要目標、架構,以及各個子模塊的設計方案。

宜搜科技搜索部架構師爬蟲組負責人 葉順平
網頁爬蟲的幾個目標是覆蓋率高、死鏈率低和實效性好,爬蟲實效性系統的目標也差不多,主要是實現新網頁快速和全面的收錄。下圖為時效性系統的整體架構:
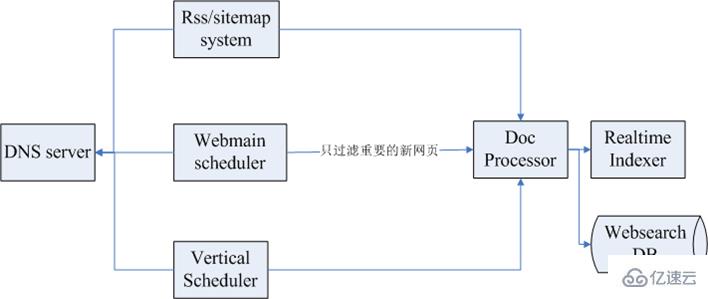
其中,上面第一個是RSS/sitemap一個子系統,接下來是網頁泛爬的調度系統Webmain scheduler,然后是一個時效性模塊Vertical Scheduler,最左側是DNS服務,抓取的時候,一般是幾十臺甚至是幾百臺的抓取集群,如果每一臺都有防御的話對DNS的壓力比較大,所以一般有一個DNS的服務模塊來做全局的服務。數據抓取完畢后,一般會做后續的數據處理。
涉及到實效性的模塊包括以下幾個:
RSS/sitemap系統:時效性系統利用RSS/sitemap的過程是挖掘種子,定時抓取,解析鏈接發布時間,將較新的網頁優先抓取并索引。
泛爬系統:泛爬系統設計良好的話有助于提高時效性網頁的高覆蓋率,但泛爬需要盡可能縮短調度周期。
種子調度系統:主要是一個時效性的種子庫,這個種子庫里面有一些信息調度系統會不斷地掃描這個數據庫,然后發給抓取集群,這個集群抓取完會進行一些抽取鏈接的處理,接下來把這些按類別發出去,各個垂直頻道會獲取到時效性的數據。
種子的挖掘:涉及到頁面解析或其它的一些挖掘手段,可以通過站點地圖,還有導航條來構建,還要基于頁面結構特征和頁面變更規律。
種子的更新機制:記錄每個種子的抓取歷史,follow的鏈接信息,定期根據種子的外鏈更新特征,重新計算種子的更新周期。
抓取系統與JavaScript解析:使用瀏覽器進行抓取,搭建一個基于瀏覽器抓取的抓取集群。或采用開源項目,如Qtwebkit。
感謝各位的閱讀!關于RSS與爬蟲怎么搜集數據就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





