溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本文主要給大家介紹mysql查詢時,offset過大影響性能怎么處理,文章內容都是筆者用心摘選和編輯的,具有一定的針對性,對大家的參考意義還是比較大的,下面跟筆者一起了解下mysql查詢時,offset過大影響性能怎么處理吧。
1.創建表
CREATE TABLE `member` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL COMMENT '姓名', `gender` tinyint(3) unsigned NOT NULL COMMENT '性別', PRIMARY KEY (`id`), KEY `gender` (`gender`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.插入1000000條記錄
<?php
$pdo = new PDO("mysql:host=localhost;dbname=user","root",'');for($i=0; $i<1000000; $i++){ $name = substr(md5(time().mt_rand(000,999)),0,10); $gender = mt_rand(1,2); $sqlstr = "insert into member(name,gender) values('".$name."','".$gender."')"; $stmt = $pdo->prepare($sqlstr); $stmt->execute();}
?>mysql> select count(*) from member;
+----------+| count(*) |
+----------+| 1000000 |
+----------+1 row in set (0.23 sec)
3.當前數據庫版本
mysql> select version(); +-----------+| version() | +-----------+| 5.6.24 | +-----------+1 row in set (0.01 sec)

1.offset較小的情況
mysql> select * from member where gender=1 limit 10,1; +----+------------+--------+| id | name | gender | +----+------------+--------+| 26 | 509e279687 | 1 | +----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 100,1; +-----+------------+--------+| id | name | gender | +-----+------------+--------+| 211 | 07c4cbca3a | 1 | +-----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 1000,1; +------+------------+--------+| id | name | gender | +------+------------+--------+| 1975 | e95b8b6ca1 | 1 | +------+------------+--------+1 row in set (0.00 sec)
當offset較小時,查詢速度很快,效率較高。
2.offset較大的情況
mysql> select * from member where gender=1 limit 100000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 199798 | 540db8c5bc | 1 | +--------+------------+--------+1 row in set (0.12 sec)mysql> select * from member where gender=1 limit 200000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 399649 | 0b21fec4c6 | 1 | +--------+------------+--------+1 row in set (0.23 sec)mysql> select * from member where gender=1 limit 300000,1; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.31 sec)
當offset很大時,會出現效率問題,隨著offset的增大,執行效率下降。
select * from member where gender=1 limit 300000,1;
因為數據表是InnoDB,根據InnoDB索引的結構,查詢過程為:
通過二級索引查到主鍵值(找出所有gender=1的id)。
再根據查到的主鍵值通過主鍵索引找到相應的數據塊(根據id找出對應的數據塊內容)。
根據offset的值,查詢300001次主鍵索引的數據,最后將之前的300000條丟棄,取出最后1條。
不過既然二級索引已經找到主鍵值,為什么還需要先用主鍵索引找到數據塊,再根據offset的值做偏移處理呢?
如果在找到主鍵索引后,先執行offset偏移處理,跳過300000條,再通過第300001條記錄的主鍵索引去讀取數據塊,這樣就能提高效率了。
如果我們只查詢出主鍵,看看有什么不同
mysql> select id from member where gender=1 limit 300000,1; +--------+| id | +--------+| 599465 | +--------+1 row in set (0.09 sec)
很明顯,如果只查詢主鍵,執行效率對比查詢全部字段,有很大的提升。
只查詢主鍵的情況
因為二級索引已經找到主鍵值,而查詢只需要讀取主鍵,因此mysql會先執行offset偏移操作,再根據后面的主鍵索引讀取數據塊。
需要查詢所有字段的情況
因為二級索引只找到主鍵值,但其他字段的值需要讀取數據塊才能獲取。因此mysql會先讀出數據塊內容,再執行offset偏移操作,最后丟棄前面需要跳過的數據,返回后面的數據。
InnoDB中有buffer pool,存放最近訪問過的數據頁,包括數據頁和索引頁。
為了測試,先把mysql重啟,重啟后查看buffer pool的內容。
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
Empty set (0.04 sec)可以看到,重啟后,沒有訪問過任何的數據頁。
查詢所有字段,再查看buffer pool的內容
mysql> select * from member where gender=1 limit 300000,1;
+--------+------------+--------+| id | name | gender |
+--------+------------+--------+| 599465 | f48375bdb8 | 1 |
+--------+------------+--------+1 row in set (0.38 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
+------------+----------+| index_name | count(*) |
+------------+----------+| gender | 261 || PRIMARY | 1385 |
+------------+----------+2 rows in set (0.06 sec)可以看出,此時buffer pool中關于member表有1385個數據頁,261個索引頁。
重啟mysql清空buffer pool,繼續測試只查詢主鍵
mysql> select id from member where gender=1 limit 300000,1;
+--------+| id |
+--------+| 599465 |
+--------+1 row in set (0.08 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
+------------+----------+| index_name | count(*) |
+------------+----------+| gender | 263 || PRIMARY | 13 |
+------------+----------+2 rows in set (0.04 sec)可以看出,此時buffer pool中關于member表只有13個數據頁,263個索引頁。因此減少了多次通過主鍵索引訪問數據塊的I/O操作,提高執行效率。
因此可以證實,mysql查詢時,offset過大影響性能的原因是多次通過主鍵索引訪問數據塊的I/O操作。(注意,只有InnoDB有這個問題,而MYISAM索引結構與InnoDB不同,二級索引都是直接指向數據塊的,因此沒有此問題 )。
InnoDB與MyISAM引擎索引結構對比圖
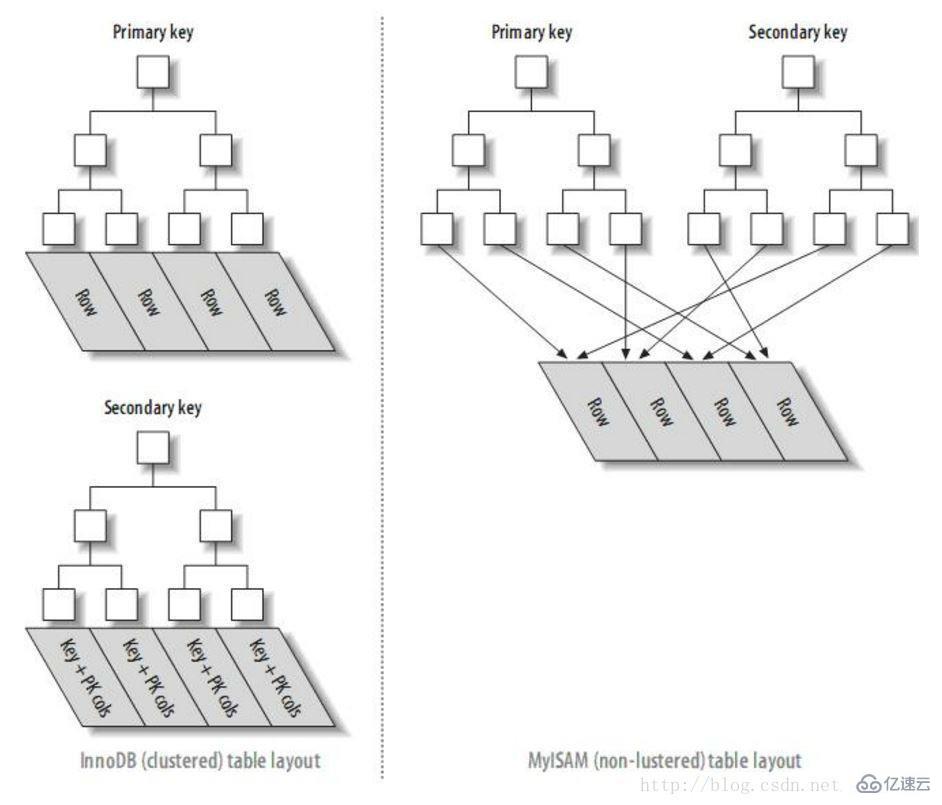
根據上面的分析,我們知道查詢所有字段會導致主鍵索引多次訪問數據塊造成的I/O操作。
因此我們先查出偏移后的主鍵,再根據主鍵索引查詢數據塊的所有內容即可優化。
mysql> select a.* from member as a inner join (select id from member where gender=1 limit 300000,1) as b on a.id=b.id; +--------+------------+--------+| id | name | gender | +--------+------------+--------+| 599465 | f48375bdb8 | 1 | +--------+------------+--------+1 row in set (0.08 sec)
看完以上關于mysql查詢時,offset過大影響性能怎么處理,很多讀者朋友肯定多少有一定的了解,如需獲取更多的行業知識信息 ,可以持續關注我們的行業資訊欄目的。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





