溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹Schema與數據類型優化的方法,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
schema就是數據庫對象的集合,這個集合包含了各種對象如:表、視圖、存儲過程、索引等。為了區分不同的集合,就需要給不同的集合起不同的名字,默認情況下一個用戶對應一個集合,用戶的schema名等于用戶名,并作為該用戶缺省schema。所以schema集合看上去像用戶名。
如果把database看作是一個倉庫,倉庫很多房間(schema),一個schema代表一個房間,table可以看作是每個房間中的儲物柜,user是每個schema的主人,有操作數據庫中每個房間的權利,就是說每個數據庫映射的user有每個schema(房間)的鑰匙。 SQL server和Oracle mysql有別
1、更小的通過更好,盡量使用可正確存儲數據的最小的數據類型(占更少的磁盤 內存 CPU緩存,處理時需要CPU周期更少:更快),但能罩得住數據,存不下就尷尬了
2、簡單就好:簡單類型(更少CPU周期),使用MySQL內建類型存時間,整型存ip,整型較字符代價低(字符集和校對排序規則使字符較復雜)
3、盡量避免null:最好指定為not null
*)null列使用更多的存儲空間,mysql里需要特殊處理
*)null使索引、索引統計和值比較更復雜;可為null的列被索引時,每個索引記錄需額外的字節
例外:InnoDB使用單獨位bit存儲null,so對于稀疏數據(很多值為null)有很好的空間效率,不適合MyISAM
tinyint(8位存儲空間) smallint(16) mediumint(24) int(32) bigint(64)
1、存儲值的范圍: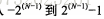
2、unsigned:可選、不容許負值,可使正數的上限提高一倍:tinyint unsigned 0~255,tinyint-128~127
3、有無符號使用相同的存儲空間,相同的性能
可為整型指定寬度,例如INT(11),對于大多數應用無意義,不會限制值的合法范圍,只是規定了交互工具顯示字符的個數,對于存儲和計算,int(1)和int(20)是相同的;
float和double,mysql使用duble作為內部浮點計算的類型
decimal:存儲精確的小數,mysql服務器自身實現,decimal(18,9)18位,9位小數,9個字節(前4后4點1)
盡量只在對小數進行精確計算時才使用(額外的空間和計算開銷),如財務數據
數據量大時,考慮使用bigint代替,將需要存儲的貨幣單位據小數的位數乘以相應的倍數
浮點:
建議:只指定類型、不定精度(mysql),這些精度非標準,mysql會悄選類型、或存時對值取舍
存儲同樣范圍的值時,比decimal更少的空間,float4字節存 double8字節(更高精度范圍)
前提:innodb和myisam引擎,最主要的字符串類型
磁盤存儲:存儲引擎存儲的方式與在內存、磁盤上的不能不一樣,所以mysql服務器從引擎取值需轉格式
varchar:
1、存儲可變字符串,比定長節省空間(僅使用必要的空間),但如果表使用row_format=fixed,行會定長存儲
2、需使用1/2額外字節記錄字符串長度;1)列max長度<=255字節,1字節表示,否2字節,2)采用latinl字符集,varchar(10)列需11個字節的存儲空間,varchar(1000)1002字節,2字節存儲長度信息
3、節省存儲空間,利于性能;但在update可能使行變得比原來更長、需做額外工作
合適的情況:
1)字符串列最大長度比平均長度大很多;2)列的更新少(不擔心碎片);3)使用UTF-8字符串,每個字符均使用不同的字節數存儲
char:
1、定長,據長度分配空間,刪除all末尾空格;長度不夠、空格填充
2、存儲空間上更有效率,char(1)來存儲只有Y N的值 1個字節 ,varchar2字節,還有一個記錄長度
適合的情況:
1)適合存儲很短的字符串;2)或all值接近同一個長度;3)經常變更的數據,存儲不易碎片
對應空格、存儲:
char類型存儲時末尾空格被刪;數據如何存儲取決于存儲引擎,Memory引擎只支持定長的行(最大長度分配空間)
binary,varbinary:存儲二進制字符串,字節碼,長度不夠、\0來湊(不是空格)檢索時不會去
慷慨不是明智的:varchar(5)和varchar(100)存儲‘hell’空間開銷一樣,長的列消耗更多內存
分別用二進制和字符方式存儲,分別屬于兩組不同的數據類型:字符類型:tinytext、smalltext、text、mediumtext、longtext,對應的二進制類型是tinyblob、smallblob、blob、mediumblob、longblob,兩類僅有的不同:blob類型存儲的是二進制,無排序規則或字符集,text有字符串 排序規則;
MySQL會把每個blob和text當做獨立的對象處理,存儲引擎存儲時會做特殊處理,當值太大,innoDB使用專門的外部存儲區域進行存儲,此時每個值在行內需要1~4個字節存儲一個指針,然后在外部存儲實際的值;
mysql對他們的列排序:只對每列前max_sort_length字節排序;且不能將列全部長度的字符串進行索引,也不能使用這些索引消除排序;
如果explain執行計劃的extra包含using temporary:這個查詢使用了隱式臨時表
定義時指定取值范圍,對1~255個成員的枚舉需要1個字節存儲;對于256~65535個成員,需要2個字節存儲。最多可以有65535個成員,ENUM類型只能從成員中選擇一個;和set相似
可把不重復的固定的字符串存儲成一個預定義的集合,mysql在存儲枚舉時會據列表值的數量壓縮到1/2字節中,在內部會將每個值在列表中的位置保存為整數(從1開始,必須進行查找才能轉換為字符串,開銷、列表小 可控),且在表的.frm文件中保持“數字-字符串”映射關系的“查找表”;
將一個數字存儲到一個 ENUM 中,數字被當作為一個索引值,并且存儲的值是該索引值所對應的枚舉成員: 在一個 ENUM字符串中存儲數字是不明智的,因為它可能會打亂思維;ENUM 值依照列規格說明中的列表順序進行排序。(ENUM 值依照它們的索引號排序。)舉例來說,對于 ENUM("a", "b") "a" 排在 "b" 后,但是對于 ENUM("b", "a"), "b" 卻排在 "a" 之前。空字符串排在非空字符串前,NULL 值排在其它所有的枚舉值前。為了防止意想不到的結果,建議依照字母的順序定義 ENUM列表。也可以通過使用GROUP BY CONCAT(col) 來確定該以字母順序排序而不是以索引值。【源】
排序時安裝創建表時的順序排序的(應該是);枚舉最不好的地方:字符串列表是固定的,添加刪除字符串須使用alter table;在‘查找表’時采用整數主鍵避免基于字符串的值進行關聯;
默認,以可排序、無歧義的格式顯示datetime:2008-01-02 22:33:44
from_unixtime將unix時間戳轉日期,unix_timestamp將日期轉unix時間戳
插入時沒有指定第一個timestamp列的值,設置為當前時間,插入記錄時,默認更新第一個timestamp列的值,timestamp類為not null,盡量使用timestamp(空間效率高);
可以使用bigint類型存儲微妙級別的時間戳,或double存秒之后的小數部分,或使用MariaDB代替MySQL;
前與tinyint同義詞,新特性
bit(1)單個位的字段,bit(2)2個位,最大長度64個位
行為因存儲引擎而異,MyISAM打包存儲all的BIT列(17個單獨的bit列只需要17個位存儲,myisam3字節ok),其他引擎Memory和innoDB為每bit列使用足夠存儲的最小整數類型來存放,不節省存儲空間;
mysql把bit當做字符串類型,檢索bit(1)值、結果是包含二進制0/1的字符串,數字上下文的場景檢索,將字符串轉成數字,大部分應用,best避免使用;

創建表時,就指定SET類型的取值范圍 :屬性名 SET('值1','值2','值3'...,'值n'),“值n”參數表示列表中的第n個值,這些值末尾的空格將會被系統直接刪除,字段元素順序 系統自動按照定義時的順序顯示 重復 只存一次。
其基本形式與ENUM類型一樣。SET類型的值可以取列表中的一個元素或者多個元素的組合。取多個元素時,不同元素之間用逗號隔開。SET類型的值最多只能是有64個元素構成的組合,根據成員的不同,存儲上也有所不同:【參考,同enum】
1~8成員的集合,占1個字節。 9~16成員的集合,占2個字節。 17~24成員的集合,占3個字節。 25~32成員的集合,占4個字節。 33~64成員的集合,占8個字節。
需要保持很多true、false值,可考慮合并這些列到set類型,在mysql內部以一系列打包的位的集合來表示的(有效利用存儲空間)且mysql有find_in_set、field函數,方便在查詢中使用;
缺點:改變列的定義代價高,需要alter table,無法再set上通索引查找
在整數列按位操作:
代替set的方式:使用整數包裝一系列的位:可把8個位包裝到tinyint中,且按位操作來使用,為位定義名稱常量來簡化這個工作,但是這樣查詢語句較難寫且難理解
1)可不用手動插入值,系統提供默認序列值;2)不要求和主鍵搭配 ; 3)要求是unique key;
4)一個表最多一個;5)類型只能是數值;5)可通過set auto_increment_increment=3;
選擇標識列類型時
考慮存儲類型、mysql對這種類型怎么執行計算和比較,確定后確保在all關聯表中使用same類型,類型間要精確匹配;
技巧:
1、整數類型:整數通常最好的選擇,很快且可使用auto_increment
2、enum和set類型,存儲固定信息
3、字符串:避免,耗空間較數字慢,myisam表特別小心(默認對字符串壓縮使用、查詢慢)
1)完全“隨機”字符串MD5/SHA1/UUID函數生成的新值 會任意分布在很大的空間內,導致insert及部分的select變慢:插入值隨機的寫到索引的不同位置,insert變慢(頁分裂 磁盤隨機訪問 聚簇索引碎片);select變慢、邏輯上相鄰的行分布在磁盤和內存不同的地方;隨機值導致緩存對all類型的查詢語句效果都變差(使緩存賴以工作的訪問局部性原理失效)
聚簇索引,實際存儲的循序結構與數據存儲的物理結構一致,通常來說物理順序結構只有一種,一個表的聚簇索引也只能有一個,通常默認都是主鍵,設置了主鍵,系統默認就為你加上了聚簇索引;【源】
非聚簇索引記錄的物理順序與邏輯順序沒有必然的聯系,與數據的存儲物理結構沒有關系;一個表對應的非聚簇索引可以有多條,根據不同列的約束可以建立不同要求的非聚簇索引;
2)存儲uuid,移除-符號,或者用unhex轉換uuid值為16字節的數字,且存儲在binary(16)列中,檢索時通過hex函數格式化為16進制格式;
UUID生成的值與加密散列函數(sha1)生成的值不同特征:uuid分布不均勻,有一定順序,不如遞增整數
嚴重性能問題,很大的varchar、關聯列不同的類型;
orm會存儲任意類型的數據到任意類型的后端數據存儲中,并沒有設計使用更優的類型存儲,有時為每個對象每個屬性使用單獨行,設置使用基于時間戳的版本控制,導致單個屬性會有多個版本存在;權衡
以上是“Schema與數據類型優化的方法”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





