溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
基于語義特征的網絡輿情正負面監測
Annie Qi
優捷信達科技研究員
在上一篇《網絡輿情正負面信息識別的方法》(詳見:http://www.eucita.com/blog)文章中,結合本人在優捷信達科技(http://www.eucita.com)研究工作,為您詳細介紹情感分析中與輿情正負面密切相關的“極性分類”。本文將延續上一篇文章的主題,詳細描述具體的正負面辨別方式,并分析優缺點,幫助您了解市場上流行“輿情監測”,”口碑監測“,“消費者調研”等信息處理系統的工作原理。
首先回顧上一章的介紹,網絡評價和信息的正負面識別,包括優捷信達科技在內的技術領先型輿情口碑監測公司,都是通過極性分類(polarity classification)這一步驟來實現,極性分類首先將具有情感傾向的相關詞語提取出來,叫做“特征提取”(feature extraction)。簡單來說,如何通過計算機判別正負面,就是通過提取句子中的正負面詞語,通過詞語的正負面來判斷文章的正負面傾向。
到目前為止,基于優捷信達科技的研究調查,目前業內主要特征提取技術分別是“基于語義”和“基于詞出現及頻率”兩種模式。本文將重點討論基于語義特征的模式,下一章將介紹基于詞的出現及其頻率的模式,并分別討論它們的優缺點。
基于語義特征的特征提取模式,也就是根據詞語表達的意思,即根據字面意思來辨析句子所表達的正負面。這一方式有三個重要的代表性方法。分別是:人工建構情感詞條的方法;PMI-IR 算法(PMI-IR Algorithm)和同義詞與反義詞方法。
1. 人工建構情感詞條
Tetsuya Nasukawa和Jeonghee Yi在2003年提出的特征提取的方法就是基于語義分析方法的原型之一。他們通過識別特定主題詞和語氣表達式之間的語義關系進行傾向性分析,采用自然語言處理技術分析特定主題和語氣詞之間的語義關聯。具體方法如下:
第一步,他們首先手動構建了一個有3513個詞條的情感詞匯表。字典中每個詞語都包括情感,詞性標記和規范形式的情感詞,比如(好,詞性標記為正面,惡劣,詞性標記為負面)。如果收錄的情感詞是一個動詞,只要通過這一動詞產生了情感,該動詞的賓語也將會被收錄(比如:優捷信達科技致力于以高科技產品滿足客戶需求。如果“致力于”作為一個收錄的情感詞并標記為正面,那么它所描述的“以高科技產品滿足客戶需求”就被認定為正面信息)。
第二步,他們使用了一些計算機工具(兩個PoS-tags和一個句子結構解析器),可以識別短語邊界和局部依賴性, 比如:針對“我喜歡打球!”這個句子,通過工具可以識別短語邊界為“打球”,“喜歡打球“,”我喜歡打球“,并且還可以分析出“打”的對象是“球”,” 喜歡”的對象是” 打球”這種短語之間的依賴關系,針對每一個句子他們只提取一個代表性的情感詞,當一個句子中存在多個情感詞時,這種方式就不夠好用。
第三步,將提取出來的情感詞,放到之前人工構建的情感詞典里檢索,找到情感詞典中對應的詞語以及它的正負面極性。這樣就完成了一個文本片段的情感極性判斷。
通過以上方法,他們實驗的準確率(精度)大約是75% - 95%,但相對檢索內容的查全率(召回率)較低,只有20% - 25%。也就是說,實驗檢索結果整體是非常準確的,但是也有大量的數據沒有抓取到,查全率較低。
因為有來自于手工設定的情感詞匯表,這種算法可以分析形容詞、副詞、名詞和動詞的情感極性。此外,他們還能理解否定句和被動句。而且,這種方法不僅可以分析情感正負面,還可以提取出正負面所對應的主題。
然而,這個系統也有幾個較為明顯的弱點。首先,這個系統需要大量的人工操作,當需要針對海量數據進行分析時,人工設定詞庫的工作量將會非常巨大。第二,盡管它可以解決否定句和被動句,但是在處理更復雜的句法結構,比如雙重否定句時,就有可能發生誤判。第三,因為查全率較低,該系統不能有效地區分哪些是對客觀事物的描述,哪些是主觀情感的抒發。導致查全率低的原因是系統的情感詞庫是由人工輸入,而讓人工輸入全部的情感詞是一件不太可能的事情。
2. PMI-IR 算法(PMI-IR Algorithm)
PMI-IR算法是特尼在2002年設計的,與第一種人工建構情感詞條的方法相比,它們特征選取方法基本相同,但是它不涉及太多人工手動工作,并且這一方法可以針對整個篇章進行分類,而不是僅僅針對一小段文字,來提取相關主題的正負面信息。
特尼將PMI-IR算法用于測定詞匯的正負面傾向性。他評估了410篇評論,獲得了74%的平均精度。他的算法的基本思路是,把情感極性待定的主觀詞提取出來,拿它和兩個情感極性計算“詞條距離”。一篇文章最終被歸類為哪個情感極性,取決于該文章里面所有形容詞性短語和副詞性短語的平均“情感傾向分值SO”(semantic orientation)。
具體步驟如下:
首先,特尼對每篇評論文章,都進行詞性標注。然后匹配兩個相鄰詞的詞性標簽,如果他們的詞性標簽符合一定的規則(詳細的規則表格過于復雜,在此不進行詳細描述),則提取為一個情感短語。
第二步,將其中的每個情感詞都看做一個可統計互信息的點,然后通過點式互信息的計算公式計算出各個情感詞和參考詞之間的互信息。點式互信息的計算公式如下所示:
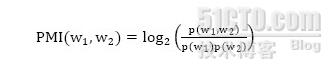
第三步,通過下面公式計算,可以得出一個詞組”w“的情感傾向分值SO,通過不同的分值,可以判斷為正面或者是負面,這樣,自動分類過程就做完了。
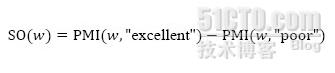
特尼的這種算法并不需要任何人工標注操作,更為重要的是,由于情感傾向分值SO(w)是一個數值,這個算法不僅能通過數值的正負數來分辨出情感的正負面,而且可以計算出情感強度,數值越高,代表正面情感越強烈。這能很好的幫助客戶評估網絡輿情正負面信息的強度。優捷信達科技的網絡輿情和口碑監測采用這一算法進行輔助評估輿情強度。
然而,由于這種算法需要計算機進行大量計算,需要投入大量的服務器資源。在特尼論文的結論部分,他還指出對電影評論的準確度低于汽車評論。主要原因是,在電影評論中出現的情感表述未必全是針對影片好壞的評價,還有可能是影片情節中的情感,比如喜劇,悲劇帶來的不同情緒。這其實是一個評述對象選擇的問題,特尼的這種方法不能很好的處理評論對象的選擇問題。
3. 同義詞與反義詞
同義詞和反義詞方法是Minqing Hu和Bing Liu在2004年提出的算法,這種方法會給每一個通過系統提取出來的主觀評價句子或者段落賦予一個情感極性。這種方法將有效地解決了網絡負擔過重的問題。
首先,當他們在某一句話中發現了情感詞,將會通過檢查情感詞數據庫(WordNet)來對這個情感詞進行分類,尋找這個詞的同義詞和反義詞,直到他們找到一個詞(可能是這個待定情感詞的同義詞或者反義詞)和這個詞已知的情感關系。這樣,新發現的情感詞就被標注為與同義詞相同的情感趨勢、與反義詞相反的情感趨勢。比如,通過系統發現一個情感詞“溺愛”,通過數據庫尋找,發現“喜愛”是“溺愛“的同義詞,而數據庫中又標注了“喜愛”的情感是正面的,那么可得“溺愛”的情感也是正面的。
第二,與之前描述的兩種方法類似,他們還基于句子中出現的情感詞所表達的情感傾向性,對每一個句子的極性進行分類。整個句子的語義傾向性是通過簡單的加權平均,將整個句子里出現的每一個情感詞的語義傾向性進行計算而得出。同上例,句子中出現了“溺愛”,沒有出現其他情感詞,那么可以認定這個句子從網絡輿情來看是正面的。
這種方法的準確率達到56% - 79%,查全率(召回率)能達到67% - 80%。盡管他們只是改進了情感詞的抓取算法,而不是情感傾向分值SO的計算方法,但是他們這種方式不需要完整搜索準確的詞,而只是通過同義詞和反義詞來判斷正負面,極大地減輕了網絡的負擔。
以上三種方式的運行原理很簡單,就是通過計算機來辨析相關詞語的正負面,然后進行統計。但是這種基于語義的方式存在很多無法徹底解決的問題,且工作量較大、實驗精度和查全率不夠高。基于此,科學界研究出另外一種特征提取方法——基于詞條出現規律的特征提取方法。這種特征提取方法忽視了詞的語義,而是重點評估出現更高頻率的詞語的情感極性。盡管這種統計方法看起來不符合我們的直覺,但卻由于在處理復雜的句法結構甚至復雜的表達結構的上佳表現,得到了業界越來越多的關注。
對于這種不太容易理解但卻表現優異的方法,優捷信達科技將在下一章進行詳細描述。您也可以通過訪問網站Http://www.eucita.com 了解詳情。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





