溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
緩存(內存 or Memcached or Redis.....)在互聯網項目中廣泛應用,本篇博客將討論下緩存擊穿這一個話題,涵蓋緩存擊穿的現象、解決的思路、以及通過代碼抽象方式來處理緩存擊穿。
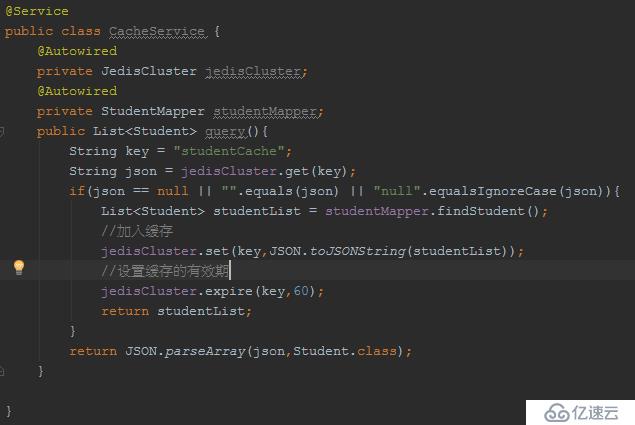
上面的代碼,是一個典型的寫法:當查詢的時候,先從Redis集群中取,如果沒有,那么再從DB中查詢并設置到Redis集群中。
注意,在實際開發中,我們一般在緩存中,存儲的數據結構是JSON。(JDK提供的序列化方式效率稍微比JSON序列化低一些;而且JDK序列化非常嚴格,字段的增減,就很可能導致反序列失敗,而JSON這方面兼容性較好)
假設從DB中查詢需要2S,那么顯然這段時間內過來的請求,在上述的代碼下,會全部走DB查詢,相當于緩存被直接穿透,這樣的現象就稱之為“緩存擊穿”!
加synchronized?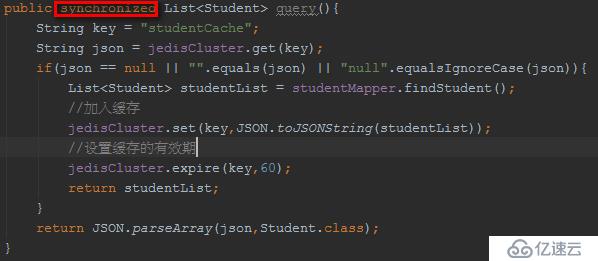
如果synchronized加在方法上,使得查詢請求都得排隊,本來我們的本意是讓并發查詢走緩存。也就是現在synchronized的粒度太大了。
縮小synchronized的粒度?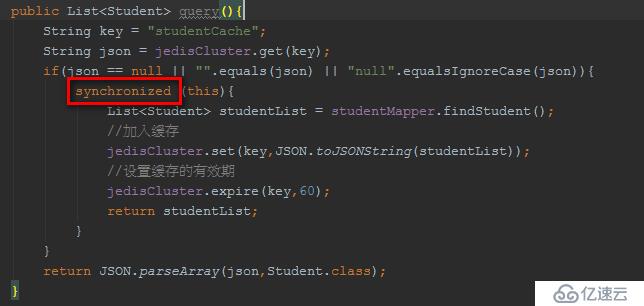
上面代碼,在緩存有數據時,讓查詢緩存的請求不必排隊,減小了同步的粒度。但是,仍然沒有解決緩存擊穿的問題。
雖然,多個查詢DB的請求進行排隊,但是即便一個DB查詢請求完成并設置到緩存中,其他查詢DB的請求依然會繼續查詢DB!
synchronized+雙重檢查機制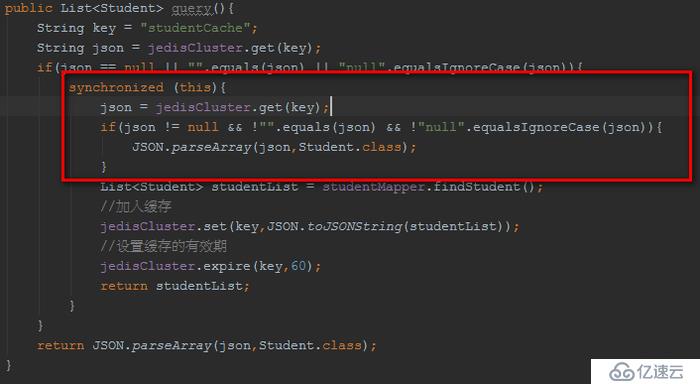
通過synchronized+雙重檢查機制:
在同步塊中,繼續判斷檢查,保證不存在,才去查DB。
發現沒有,其實我們處理緩存的代碼,除了具體的查詢DB邏輯外,其他都是模板化的。下面我們就來抽象下!
一個查詢DB的接口:
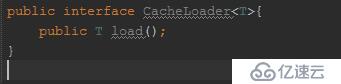
既然查詢具體的DB是由業務來決定的,那么暴露這個接口讓業務去實現它。
一個模板:
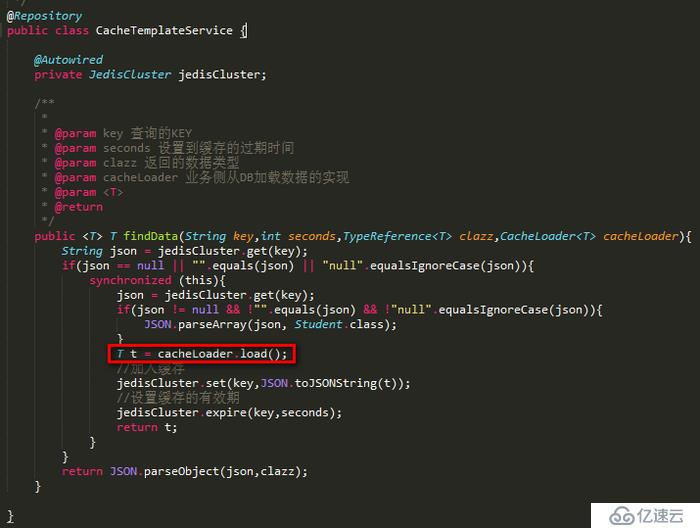
Spring不是有很多Template類么?我們也可以通過這種思想對代碼進行一個抽象,讓外界來決定具體的業務實現,而把模板步驟寫好。(有點類似AOP的概念)
改進后的代碼:
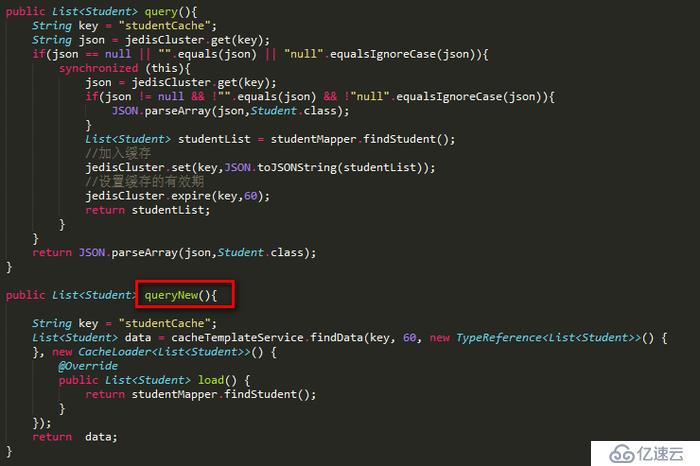
從這里可以看出,我們并不關心緩存的數據從哪里加載,而是交給具體的使用方,而且使用方在使用時再也不必關注緩存擊穿的問題,因為我們都給抽象了。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





